The point of it...
The aim is to filter your corpus by checking which of certain words or phrases are found or not found in each text. It operates a scoring system. You specify words or phrases which you believe are typical of the field you're investigating and can specify some which you see as unwanted distractors. Text files which score highly can then be copied or moved to a location of your choice.
Settings
Choose a list of filter strings, a minimum word count, a suitable division into segments, and optionally a table of the search-phrases by date.
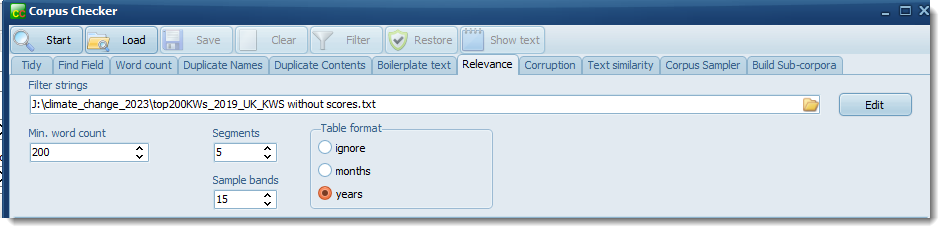
segments: a number of equal-size segments of each text which any hits must be found in.Here, the settings mean the texts will be segmented into 5 sections (the first 20%, the second 20% and so on). The more segments a given term is found in, the higher the score. With 5 segments, the score is multiplied by 4 if two segments are found, by 9 if three, by 16 if four and by 25 if five.
Sample bands: this number lets you break down scores into bands when getting an .RTF sample or a Chart.
Table format: by months or years as measured by the file-date.

Which texts to consider?
When you press the  button you will get a choice between all the text files in a folder and sub-folders, or a previously-made list, such as that created in the Corpus Sampler procedure.
button you will get a choice between all the text files in a folder and sub-folders, or a previously-made list, such as that created in the Corpus Sampler procedure.
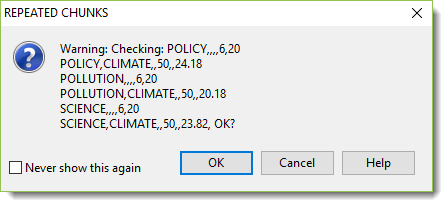
Display
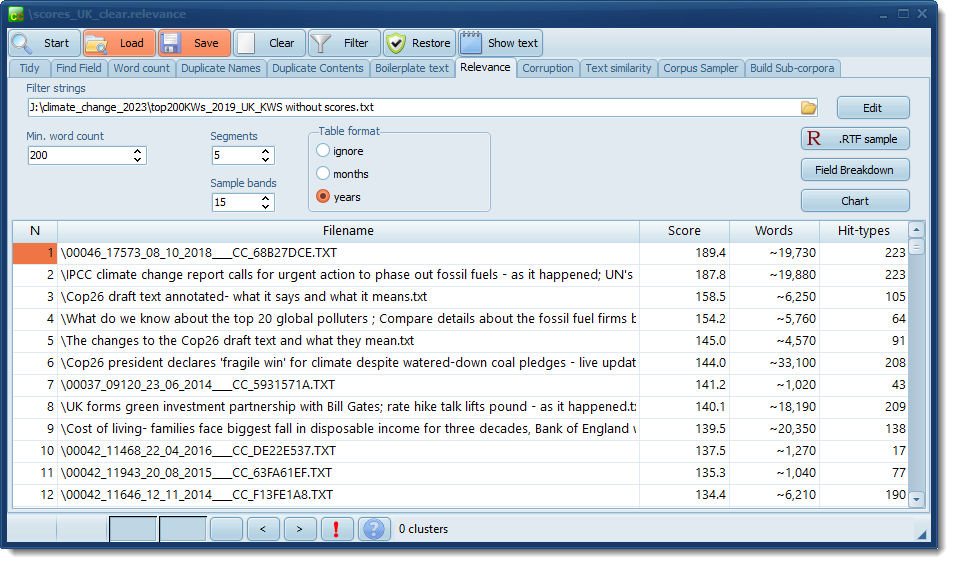
The display shows scores, number of words and number of different hit-types found. The score is just a number. It will vary according to how much value you attach to a search-term, the number of search terms you seek.
If you choose a month or year table format you also get a table for the search-terms.
Example
I was studying austerity in news text. Lots of articles mentioned austerity, sometimes incidentally. And I wanted to study austerity in Britain but a lot of articles concerned Greece. So my filters had terms like cost-cutting, UK etc. and my negative filters included Greek, Greece etc. To get a suitable corpus I wanted quite a lot of the positive terms I preferred and few of the negative ones. After the relevance check was done I was able to filter out most of the texts leaving only ones which were much more relevant to my enquiry.
Filter relevant texts button
RTF Sample button
To see one of the texts simply select it and press the  button. When it appears you can right-click to Highlight all search-terms. After highlighting all, we get
button. When it appears you can right-click to Highlight all search-terms. After highlighting all, we get
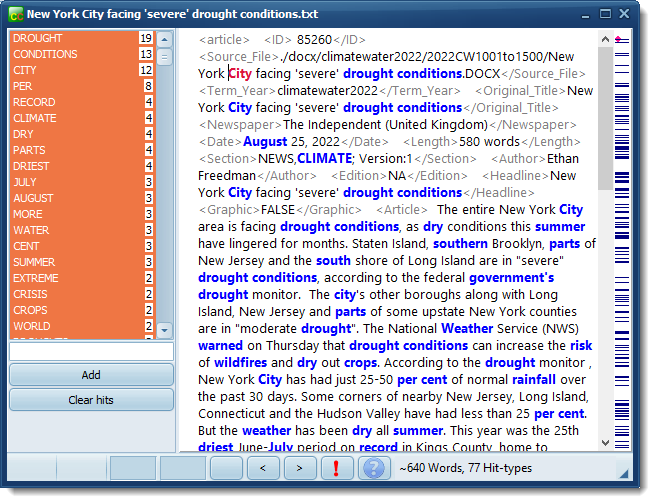
You see the search terms coloured, and to the right a dispersion plot showing where they appear in the text.
Limitation
The procedure uses search-terms. It doesn't actually understand the text. All it can do is give a higher score to the presence of positive terms and reduce the score if negative ones are found. Texts about the environment don't necessarily contain the word environment!
Choosing your relevance filters
A useful idea is to compute the key words and key clusters of your imperfect corpus first. That will help you find words and phrases that characterise your corpus. Use some of them plus any others you think will be plausible. Also, read a sample of texts carefully to check what sort of corpus you really got.
Finally try the relevance filter. You can sample the texts to see how well you're doing. Edit the relevance filters to refine them.
See also: RTF sample, corpus sampler, which helps you separate the desired sample out.