Tags for your text
Each tag you define has to match the structure of your text. If it doesn't match you won't get the results you want.
 detailed explanation
detailed explanation
If your corpus is formatted like this
some_DD parts_NN2 of_IO Britain_NP1
then you may wish to get it re-structured (easily & quickly) like this
<DD>some <NN2>parts <IO>of <NP1>Britain
using the Text Converter.
If your corpus has lots of mark-up within each < > like this
<w c5="VVG-NN1" hw="shiver" pos="VERB">shivering </w><w c5="VBZ" hw="be" pos="VERB">is </w>
<w c5="AT0" hw="a" pos="ART">a </w><w c5="NN1" hw="body" pos="SUBST">body </w>
<w c5="NN1" hw="reaction" pos="SUBST">reaction
you need to know how many attributes there are for each piece of mark-up. In this case (BNC XML) we have a four: w then an attribute beginning c5 and ending " then lemma information beginning hw, and a pos section. Each attribute can be handled with an asterisk. So you might have to tell WordSmith to find <w c5="NN1" * *>*. That means, "find me a stretch beginning <w c5="NN1" with any two following attributes, then a closing > and do not require a word-break after it." This is explained also in the XML text section.
|
Tag Syntax
Each tag is case sensitive.
Tags conventionally begin with < and end with >. You will be asked to confirm any tag with different first & last characters.
The ideal format for use with WordSmith, for single-word mark-up, is <TAG>word. In other words your tag immediately precedes the word it refers to. Tag as prefix to word. For longer stretches, <OPENING_TAG>blah blah blah</OPENING_TAG>. In other words a tag is used to signal the start of mark-up, and / plus the same tag is used to signal the end.
You can use
* to mean any sequence of characters;
? to mean any one character;
# to mean any numerical digit.
Don't use [ to insert comments in a tag file, since [ is useful as a potential tag symbol. You can use # to represent a number (e.g. <h#> will pick up <h5>, <h1>, etc.). And use ? to represent any single character (<?> will pick up <s>, <p>, etc.), or * to represent any number of characters (e.g. <u*> will pick up <u who=Fred>, <u who=Mariana>, etc.). Otherwise, prepare your tag list file in the same way as for Stop Lists.
Use notepad or any other plain text editor, to create a new .tag file. Write one entry on each line.
Any number of pre-defined tags can be stored. But the more you use, the more work WordSmith has to do, of course and it will take time & memory ...
Mark-up to INclude
A tag file for tags to retain contains a simple list of all the tags you want to retain. Sample tag list files for BNC handling (e.g. BNC_XML.tag) are included with your installation (in your Documents\wsmith8 folder): you could make a new tag file by reading one of them in, altering it, and saving it under a new name. The syntax is explained in BNC_XML.tag.
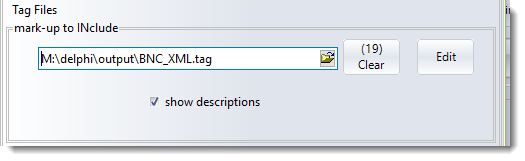
Here a tag file has been loaded; it had 19 entries.
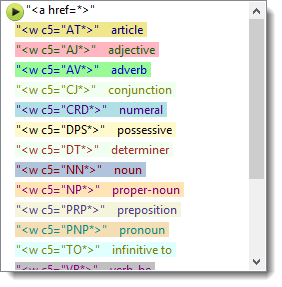
and here is a word list based on BNC spoken classroom data where the tag file was used:
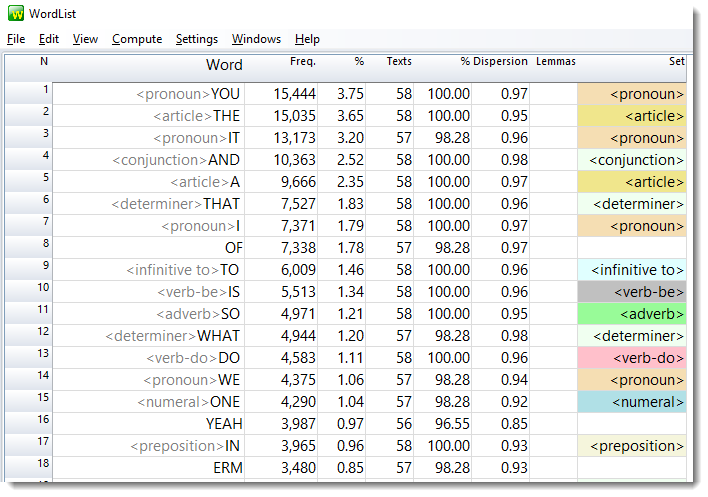
Here is a concordance using the Noun tag:

... easy to see adjectives come before nouns...
You can hide the tags and keep the colours using View | Tag hiding | Tagfile tags. See tag colours.
if <tag>WORD
... this means, if a tag is found immediately to the left of a word (such as <VERB>wanting for example), WordSmith can by default treat the <VERB> tag as a tag, or can ignore the word, only recording the tag. This is useful if you do not want to keep the words but are only interested in their tags.
|
Mark-up to EXclude
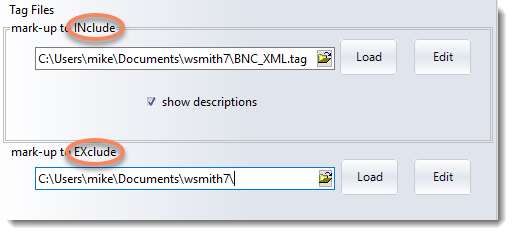
A tag file for stretches of mark-up like this <SCENE>A public library in London. A bald-headed man is sitting reading the News of the World.</SCENE>
where you want to exclude the whole stretch above from your concordance or word list, e.g. because you're processing a play and want only the actors' words. Mark-up to exclude will cut out the whole string from the opening to the closing tag inclusive.
For the Shakespeare corpus, a set of tags to EXclude might be used.
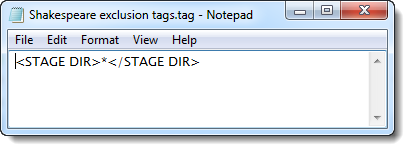
(The idea is not to process any stage directions when processing the Shakespeare corpus.)
The syntax requires ></ or >*</ to be present.
Legal syntax examples would be:
<SCENE></SCENE>
<SCENE>*</SCENE>
<SCENE #>*</SCENE>
<HELLO?? #>*</GOODBYE>
(In this last example it'll cut only if <HELLO is followed by 2 characters, a space and a number then >, and if </GOODBYE> is found beyond that.)
<SCENE>*
</SCENE>
won't work, because both parts of the tag must be on the same line.
<SCENE>*<\SCENE>
won't work, because the slash must be /.
With your installation you will find (Documents\wsmith8\sample_lemma_exclude_tag.tag) included, which cuts out lemmas if constructed on the pattern <lemma tag="*>*</lemma>, i.e. with the word tag, an equals sign and a double-quote symbol, regardless of what is in the double-quotes.
|
Colours
Tags will by default be displayed in a standard tag colour (default=grey) but you can specify the foreground & background for tags which you want to be displayed differently by putting
/colour="foreground on background"
e.g. <noun> /colour="yellow on red"
Available colours can be seen in the list of colours in the colours tab.
The colour names are not case sensitive (though the tags are). Note UK spelling of "grey" and "colour".
|
Sound and Video
Also, you can put "/play media" if you wish a given tag, when found in your text files, to be able to attempt to play a sound or video file. For example, with a tag like
<sound *> /colour="blue on yellow" /play media
and a text occurrence like
<sound c:\windows\Beethoven's 5th Symphony.wav>
or
<sound http://www.political_speeches.com/Mao_Ze_Dung.mp3>
you will be able to choose to hear the .wav or .mp3 file.
|
Descriptive Label
Finally, you can put in a descriptive label, using /description like this:
<w NN*> /description "noun" /colour="Cream on Purple"
<ABSTRACT> /description "section"
<INTRODUCTION> /description "section"
<SECTION 1> /description "section"
Show descriptions
If you define a description, WordSmith will by default show that instead of the formal tag. The "Show descriptions" check box switches on or off the renaming of your tags to the format in the description section you define.
|
Section Tag
In the examples using "section", Concord's "Nearest Tag" will find the section however remote in the text file it may be.
This is particularly useful e.g. if you want to identify the speech of all characters in a play, and have a list of the characters, and they are marked up appropriately in the text file.
<Romeo> /description "section"
<Mercutio> /description "section"
<Benvolio> /description "section"
|
Tagstring_only tags
You can also define two tags as ones you want to use to mark the beginnings and ends of what will be shown in a concordance using /tagstring_only as a signal. For example, if concordancing text containing titles marked out with <title> and </title>, you may want to see only the title text. You'd include in the tag file
<title> /tagstring_only
</title> /tagstring_only
To get Concord to show only the text between these two, choose View | Tag string only in Concord's menu.
|
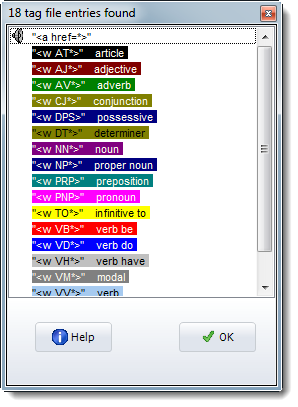
Here is an example of what you see after selecting a tag file and pressing "Load". The first tag is a "play media" tag, as is shown by the icon. You can see the cream on purple colour for nouns too. The tag file (BNC World.tag) is included in your installation.
Entity File (entities to be translated)

If you load it you might see something like this:
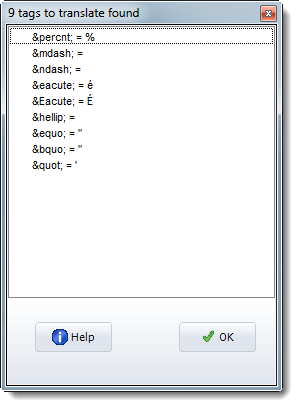
A tag file for translation of one entity reference into another uses the following syntax: entity reference to be found + space + replacement. Examples:
É É
é é
In the screenshot above, the sample tag file for translation (Documents\wsmith8\sgmltrns.tag) which is included with your installation has been loaded. You could make a new one by reading it in, altering it, and saving it under a new name.
|
See also: Overview of Tags, Handling Tags, Showing Nearest Tags in Concord, Tag Concordancing, Types of Tag, Viewing the Tags, Using Tags as Text Selectors, Guide to handling the BNC.