The point of it
The idea (from Michaela Mahlberg and her team at Birmingham) is to find out which collocates in your current list are also present in another set of data.
How to do it
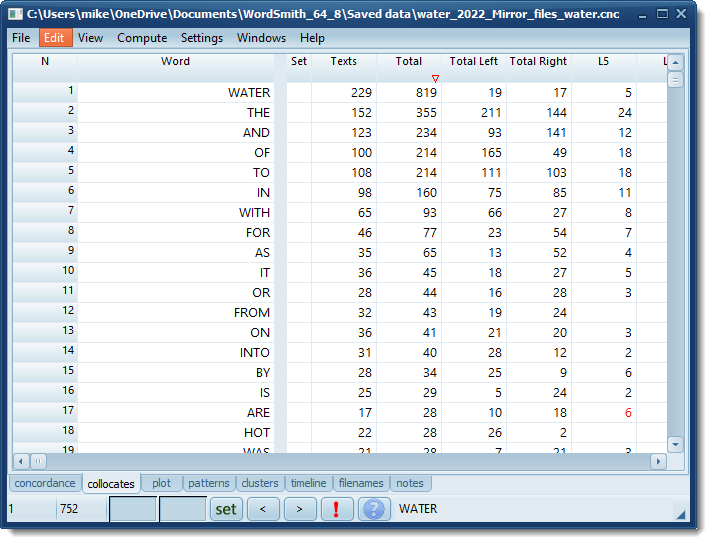
With a collocate listing on screen, choose Compute | Collocates...| Compare with other list. Choose the concordance file (.cnc) which contains the collocates. The program matches all collocates in the other list with the list on screen. If they are found, it computes the percentage of each collocate as a percentage of the total of all collocates and puts a coloured value in the Set column.
Here a collocate list based on Guardian text was compared with the collocate list from the Daily Mirror, studying the same corpus.
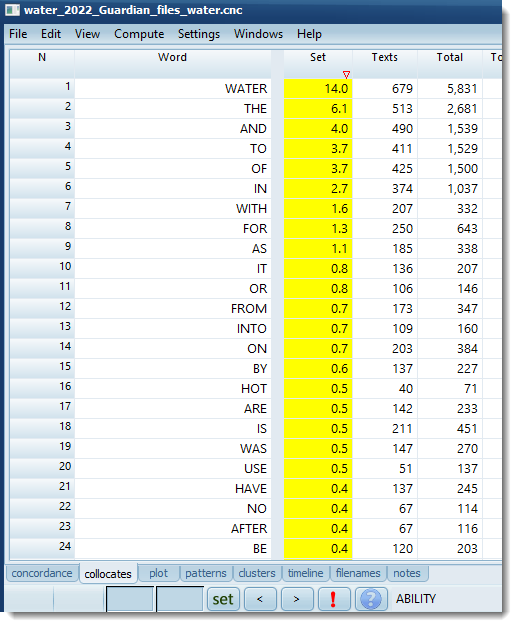
The numbers in yellow (it's timeline quantity peak fill colour) show all cases where the same collocate is present in both .cnc files. WATER is 14% of the collocates in the Daily Mirror set.


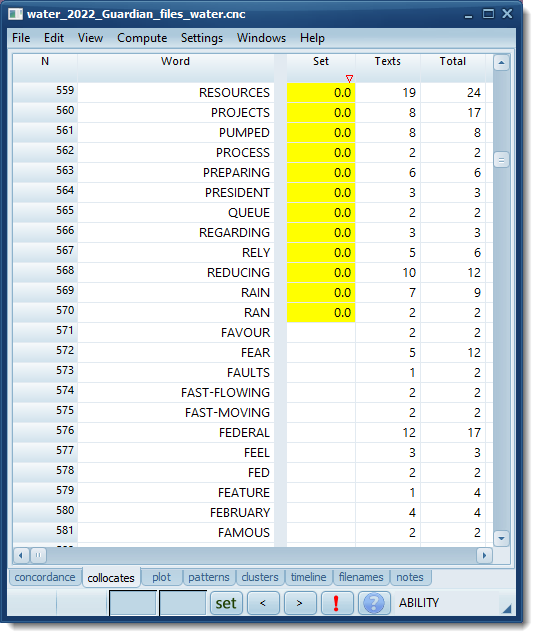
At the bottom of the sorted Set column listing, you get the collocates which were only present in the original .cnc data. Here, RAN is present (but less than 0.05% of the Mirror collocates) in both but FAVOUR, FEAR, FAULTS etc. are only in the original Guardian data.