
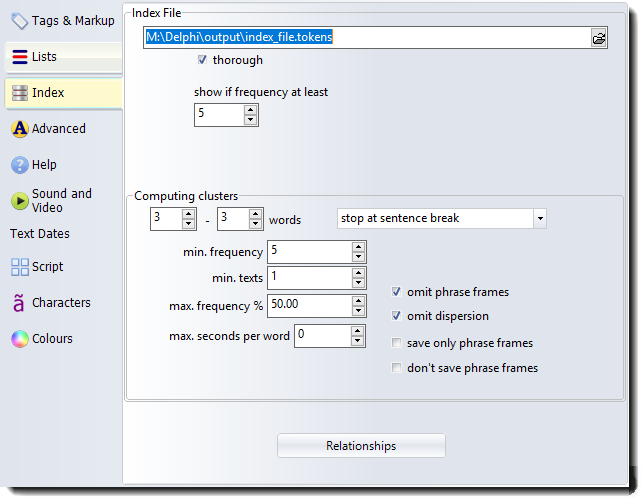
Index File
The filename is for a default index which you wish to consider the usual one to open.
thorough concordancing: when you compute a concordance from an index, you will either get (thorough checked) or not get (if not checked) full sentence, paragraph and other statistics as in a normal concordance search. (Computing these statistics takes a little longer.)
show if frequency at least: determines which items you will see when you load up the index file. (What you see looks like a word list but it is reading the underlying index.)
Clusters
the minimum and maximum sizes are 2 and 8. Set these before you compute a multi-word word list based on the index. A good maximum is probably 4 or 5.
min. frequency: minimum frequency for each cluster.
min. texts: minimum number of texts a cluster must be in.
stop at: you can choose where you want cluster breaks to be assumed. With the setting above (no limits), "I wrote the letter. Then I posted it" would consider letter then I posted as a possible multi-word string even though there's a sentence break between them.
max. frequency %: saves processing very high frequency words. (THE in most English text takes up about 5%, so a setting of 3% will save computing clusters which start with the topmost frequency words.)
max. seconds per word: a setting allowing you to ignore high-frequency items which occur so often that procesing slows down. (0=no limit)
omit phrase frames: (default = checked) avoids showing phrase frames in a word cluster list.
omit dispersion: (default = not checked) avoids computing dispersion scores in an index.
save only phrase frames: (applies when saving a word list of clusters)
don't save phrase frames: (applies when saving a word list of clusters)
Relationships
See also: WordList index
