|
Clusters in Concord ( |

|

|

|
|
Clusters in Concord ( |
|
|
|
The point of it…
These word clusters help you to see patterns of repeated phraseology in your concordance, especially if you have a concordance with several thousand lines. Naturally, they will usually contain the search-word itself, since they are based on concordance lines.
Another feature in Concord which helps you see patterns is Patterns.
How it does it…
Clusters are computed automatically if this is not disabled in the main Controller settings for Concord (Adjust Settings | Concord) where you will see something like this:
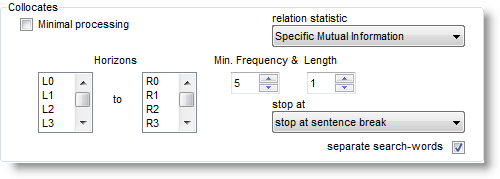
where your usual default settings are controlled. "Minimal processing", if checked, means do not compute collocates, clusters, patterns etc. when computing a concordance. (They can always be computed later if the source text files are still present.)
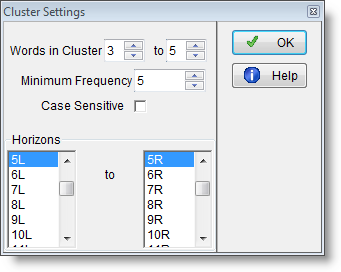
Clusters are sought within these limits: default: 5 words left and right of the search word, but up to 25 left and 25 right allowed. The default is for clusters to be three words in length and you can choose how many of each must be found for the results to be worth displaying (say 3 as a minimum frequency).
Clusters are calculated using the existing concordance lines. That is, any line which has not been deleted or zapped is used for computing clusters.
As with WordList index clusters, the idea of "stop at sentence breaks" (there are other alternatives) is that a cluster which spans across two sentences is not likely to make sense.
The default clusters computed may not suit, (and you may want to recompute after deleting some lines), so you can also choose Compute | Clusters (
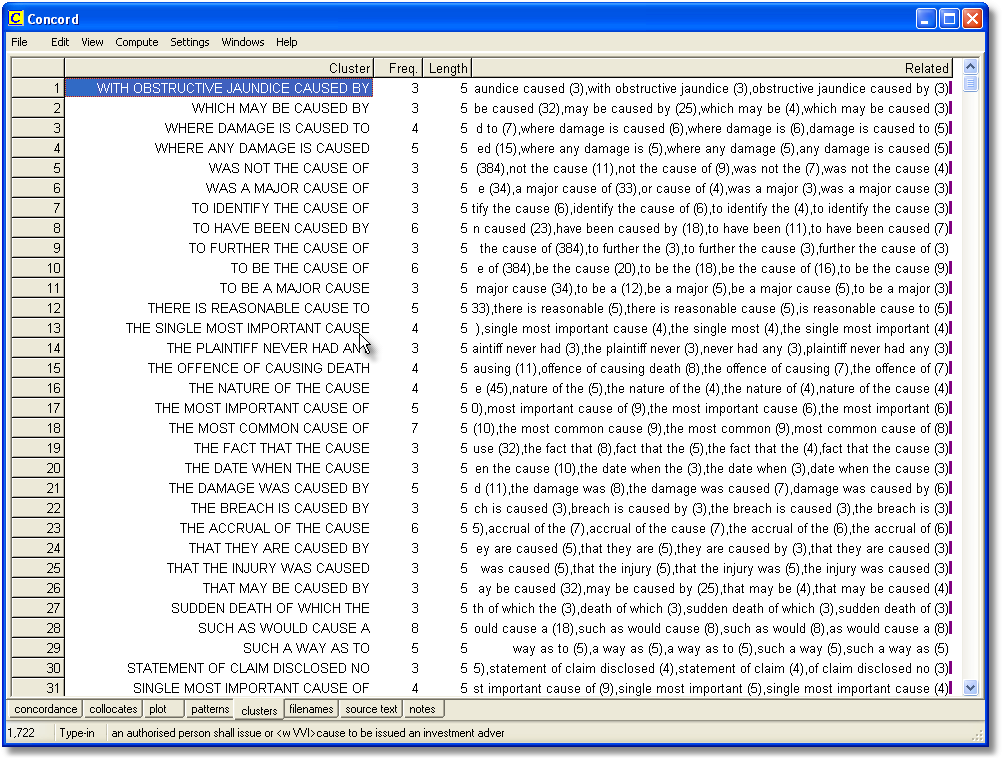
When you press OK, clusters will be computed. In this case we have asked for 3- to 5-word clusters and get results like this:
The clusters have been sorted on the Length column so as to bring the 5-word clusters to the top. At the right there is a set of "Related" clusters, and for most of these lines it is impossible to see all of their entries. To solve this problem, double-click any line in the Related column and another window opens. Here is the window showing what clusters are related to the 3-word cluster, the cause of, which is the most frequent cluster in this set:
"Related" clusters are those which overlap to some extent with others, so that the cause of overlaps with devoted to the cause of, etc. The procedure seeks out cases where the whole of a cluster is found within another cluster. |
See also: general information on clusters, WordList Clusters.
Page url: http://www.lexically.net/downloads/version5/HTML/?concord_clusters.htm