 WordSmith Tools handles a very wide range of languages, ranging from Albanian to Zulu. Chinese, Japanese, Arabic etc. are handled in Unicode.
WordSmith Tools handles a very wide range of languages, ranging from Albanian to Zulu. Chinese, Japanese, Arabic etc. are handled in Unicode.
The point of it …
1. Different languages sometimes require specific fonts.
2. Languages vary considerably in their preferences regarding sorting order. Spanish, for example, uses this order: A,B,C,CH,D,E,F,G,H,I,J,K,L,LL,M,N,Ñ,O,P,Q,R,S,T,U,V,W,X,Y,Z. And accented characters are by default treated as equivalent to their unaccented counterparts in some languages (so, in French we get , etc.) but in other languages accented characters are not considered to be related to the unaccented form in this way (in Czech we get ..)donne, donné, données, donner, donnezcesta .. cas .. hre .. chodník
Sorting is handled using Microsoft routines. If you process texts in a language which Microsoft haven't got right, you should still see word-lists in a consistent order.
Note that case-sensitive means that will come after Zebra.
It is important to understand that a comparison of two word-lists (e.g. in KeyWords) relies on sort order to get satisfactory results -- you will get strange results in this if you are comparing 2 word-lists which have been declared to be in different languages.
Settings
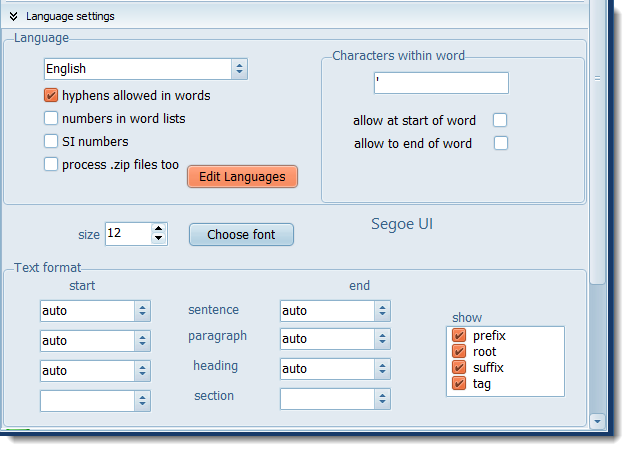
Hyphens separate words, Numbers, Characters within word
Not English?
Choose the language for the text you're analysing in the Controller under Language Settings.
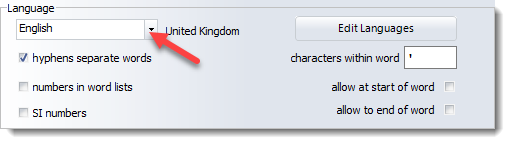
If the list which opens up where the red arrow shows doesn't include your language, press Edit languages.
The language and character set must be compatible, e.g. English is compatible with Windows Western (1252), DOS Multilingual (850).
You can view word lists, concordances, etc. in different languages at the same time.
See also: Choosing Accents & Symbols, Accented characters, Processing text in Chinese etc., Text Format, Changing language of saved data