The tool works in any language. It checks corruption by using a known sample of good text (in whatever language) and comparing that good text with all your corpus.
1. Choose a set of "known good text files" which you're sure of. The program uses these to evaluate the others.
When you click the button for known good text files, you can choose a number. You might choose 20 good ones so as to get a lot of information about what your corpus is like.
2. Choose your corpus head folder and check the "include sub-folders" box if your corpus spreads over that folder and sub-folders.
3. The program will anyway look out for oddities such as a text file which has holes in it, eg. where the system thinks it's 1000 characters long but there are only 700.
4. If you check the "digraph check" box it will additionally check that the pairs of letters (digraphs) are of roughly the right frequency in each text file. For example there should be a lot of TH combinations if your text is in English, and no QF combinations. If you are working with a corpus in Portuguese and your text files are in Portuguese too, of course the digraphs will be different, and TH won't be frequent. The program ignores punctuation.
5. If you are doing a digraph check you can vary certain parameters such as how much variation there may be between the frequencies of the digraphs (a sensible setting for "frequency variation per 1000" could be 30 (in other words 3%)), and "percent fail allowed" (which might be set at say 25 -- this means that up to 25% of the digraph pairs may be out of balance before an alert is sounded).
6. Press Start.
You will see the progress bar moving forward.
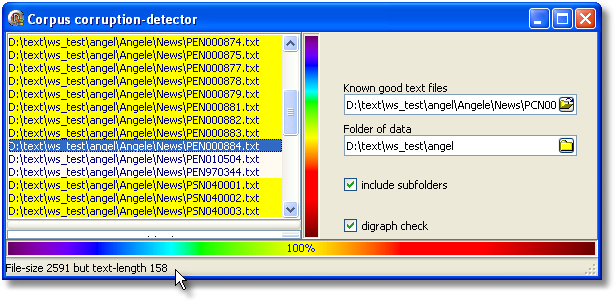
If you see a file-name in the top-left box, a click on it will indicate why it was found questionable. Double-clicking it will open up the text in the window below so you can examine it carefully.
File-names of possibly corrupted texts are yellow if the basic check fails, and cream-coloured if the reason is because of a diagraph mis-match.
In the screenshot, PEN000884.txt is problematic because the file-size on disk is 2591 (there should be 2591 characters) but there are only 158, as shown in the statusbar at the bottom.
In the case of PEOP020151.txt, the text appears below (after double-clicking the list),
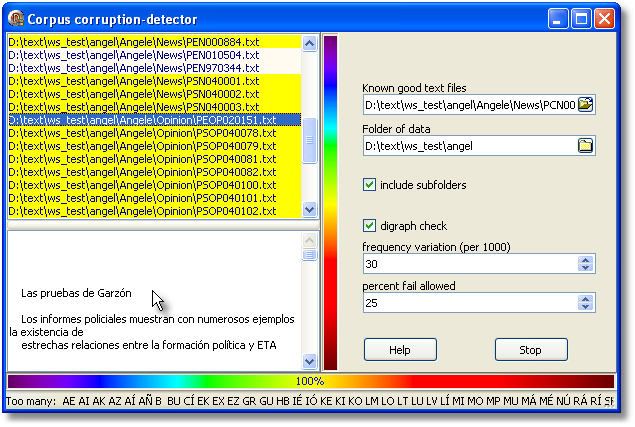
and the status bar says the tool has found an imbalance in the digraphs. The text itself has a lot of blank space at the top but otherwise looks OK (it is supposed to be in Spanish) but the detector has flagged it up as possibly defective.