|
Using Tags as Text Selectors |

|

|

|
|
Using Tags as Text Selectors |
|
|
|
Defaults
The defaults are: select all sections of all texts selected in Choose Texts but cut out all angle-bracketed tags.
Custom settings
There are various alternatives in this box which help your choices with the boxes below. Choosing British National Corpus World Edition (as in the screenshot) will for example automatically put </teiHeader> into the Document header ends box below. You can also edit the options and their effects.
Markup to ignore
If you want to cut out unwanted tags eg. in HTML files, leave something like < > or [ ] or < >;[ ] in Markup to ignore. The "search-span" means how far should WordSmith look for a closing symbol such as > after it finds a starting symbol such as <. (The reason is that these symbols might also be used in mathematics.)
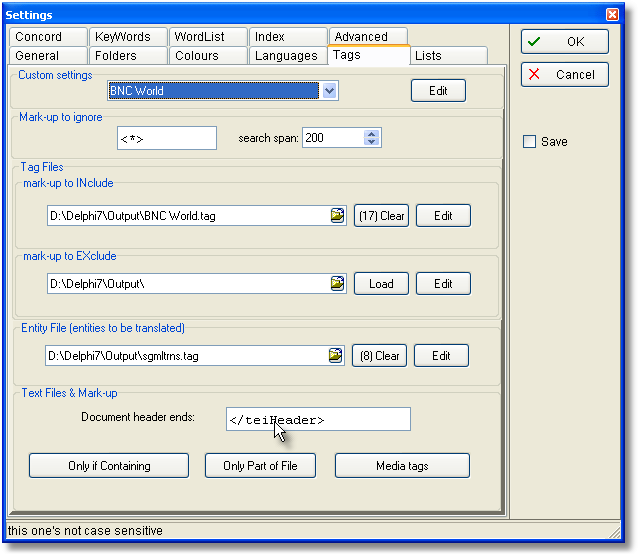
Markup to INclude or EXclude
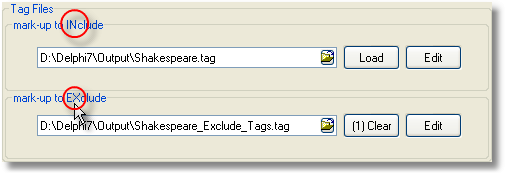
See Making a Tag File.
Entity file

See Making a Tag File.
Text Files and Mark-up
However, you can get WordSmith to use tags to select one section of a text and ignore the rest. This is "selecting within texts". You can also select between texts: that is, get WordSmith to look within the start of each text to see whether it meets certain criteria.
These functions are available from Settings | Adjust Settings | Tags | Only If Containing or Only Part of File.
Document Header
If you simply want to cut out a document header (a repeated header containing copyright notices as is found at the start of every BNC text), you just ensure that some suitable tag is specified as above in the </teiHeader> example. (If you choose Custom Settings above, you will get suitable choices automatically.)
For more complex searches, you might want to choose the Only If Containing or Only Part of File buttons visible above.
The order in which these choices are handled
If you choose either to select either between or within texts, WordSmith will check that each text file meets your requirements, before doing your concordance, word list, etc. It will
1. Select between files to check whether it contains the words you've specified;
2. Cut out any section specified as a "section to cut";
3. If there are "sections to keep", cut out everything which is not within them;
4. Cut start of each line, if applicable;
5. Process any entity references you want to translate;
6. Ignore any tags not to be retained (see the "Mark-up to ignore" section of the screenshot above).
See also: Overview of Tags, Making a Tag File, Tag Handling, Tag Concordancing, Showing Nearest Tags in Concord, Viewing the Tags, Types of Tag, Guide to handling the BNC
Page url: http://www.lexically.net/downloads/version5/HTML/?tags_as_selectors.htm

