|
summary statistics |

|

|

|
|
summary statistics |
|
|
|
The idea is to be able to break down your concordance data. For example, you've just done a concordance of consequence? which has given you lots of singulars and lots of plurals and you want to know how many there are of each.
Choose Summary Statistics in the Compute menu.
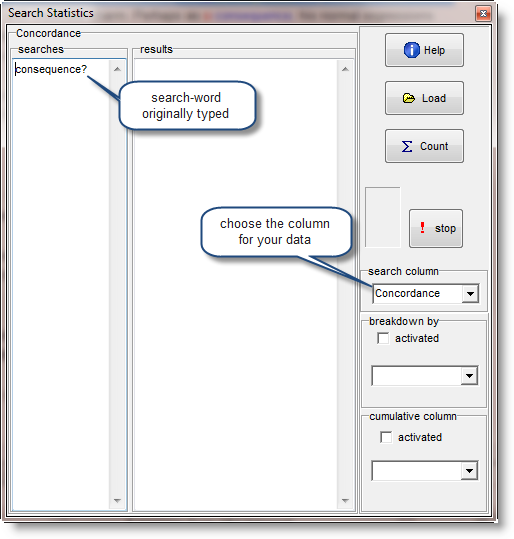
The searches window will at first contain a copy of what you typed in when you created the concordance. To distinguish between singular and plural, change that to
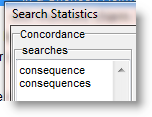
and press Count;
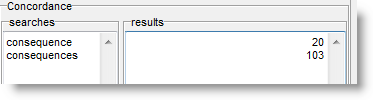
assuming that search column has Concordance selected, you will get something like this:
![]() Advanced Summary Statistics features
Advanced Summary Statistics features
Breakdown The idea here is to be able to break down your results further, using another category in your existing concordance data, such as the files the data came from. In our example, we might want to know for consequence and consequences, how many of the text files contained each of the two forms.
To generate the breakdown, activate it and choose the category you need.
The results window will now show something like this
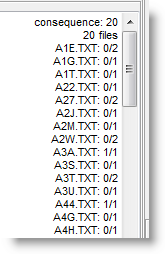
where it is clear that the singular consequence came 20 times in 20 different files, the first being file A3A.TXT. Further down you will find the results for consequences:
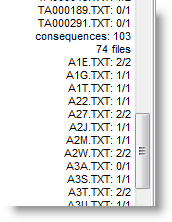
which appeared 103 times in 74 files, and that in the first of these, A1E.TXT, it came twice.
Cumulative column see the explanation for WordList
Load button see the explanation for count data frequencies. |
Page url: http://www.lexically.net/downloads/version5/HTML/?summary_statistics.htm