WordList > mutual information: computing
In WordList or in Concord
In Concord
MI is not computed by default for a collocate list. To compute MI, you need a word list to supply the relevant data.
Suppose you have made a concordance using all the files in c:\wsmith4\text\shakespeare and have done a concordance on love. You get collocates such as Romeo, hate, the, Juliet, Nurse etc. All these show a "Relation" (MI) score of "??" because they haven't yet been computed.
If you haven't done so yet, use WordList to make a word list of the same text files (or if you prefer, use some other reference corpus). Make sure the reference corpus file is what you prefer.
Now choose the menu item ![]() and Concord will use the reference corpus filename. It will look up each of your collocates in the word list and compute MI using the information in the reference corpus word list.
and Concord will use the reference corpus filename. It will look up each of your collocates in the word list and compute MI using the information in the reference corpus word list.
In WordList
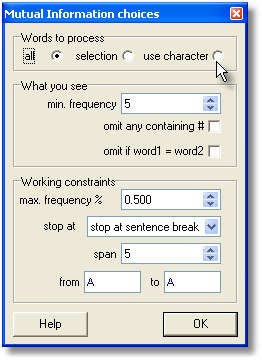
To compute Mutual Information (MI) you need a WordList Index. Call up the alphabetical view of the list.
When you press ![]() , you can choose whether to compute MI for selected (highlighted) entries, for all entries, or for those between two initial characters e.g. between A and D.
, you can choose whether to compute MI for selected (highlighted) entries, for all entries, or for those between two initial characters e.g. between A and D.
If you wish to select only a few items for MI calculation, you can mark them first (with ![]() ).
).
You can always do part of the list (eg. A to D) and later merge your mutual-information list with another (E to H).
What you see: set the minimum frequency to suit the frequency, e.g. 5 means that no word of frequency 4 or less in the index will be visible in the MI results. Omit # means no numbers will be considered, and omit if word1=word2 is there because you might find that GOOD is related to GOOD if there are lots of cases where these 2 are found near each other.
Working constraints: this is to set things so that the process doesn't take forever, as explained below. Max. frequency = ignore high frequency words which would occur say at 0.5% frequency. (Above 0.5% in the case of the BNC would mean ignoring about 20 of the top frequency words, such as WITH, HE, YOU. Above 0.1% would cut about 100 words including GET, BACK, BECAUSE.)
Stop at has to do with whether breaks such as punctuation or sentence breaks determine that one word cannot be related to another; to suit the frequency, e.g. 5 means that no word of frequency 4 or less in the index will be used in the MI results. Span is how far left and right to look for the MI relation. From A to A is where you choose a range of words starting with those characters.
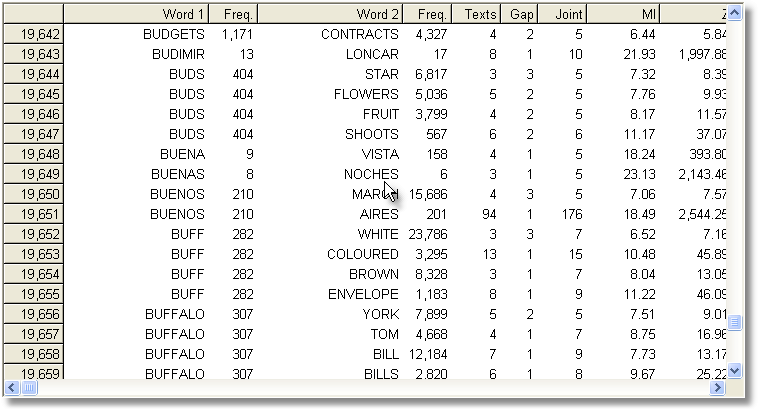
Computing the MI score for each and every entry in an index takes a long time: it took over an hour to compute MI for all words beginning with B in the case of the BNC World edition (written, 90 million words) in the screenshot below, using the settings visible above. It might take 24 hours to process the whole BNC, 100 million words, even on a modern powerful PC. Don't forget to save your results afterwards!
See also Collocates, Mutual Information Settings, Mutual Information Display, Making an Index List, Viewing Index Lists, WordList Help Contents.