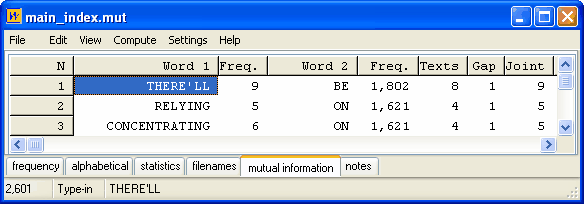
The "Mutual Information" procedure contains a number of columns and uses various formulae:
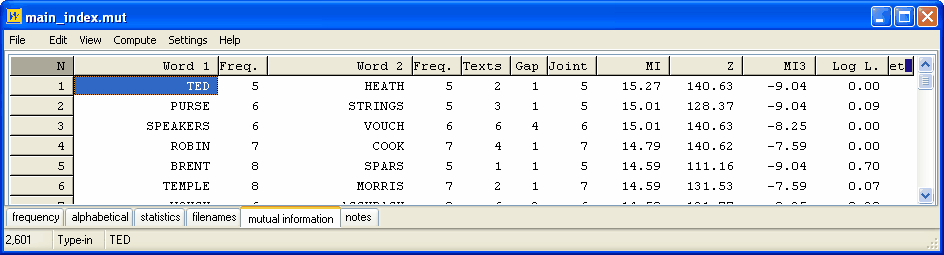
Word 1: the word to the left, followed by Freq. (its frequency in the whole index).
Word 2: the word to the right, followed by Freq. (its frequency in the whole index).
Texts: the number of texts this pair was found in (there were 56 in the whole index).
Gap: the most common distance between Word 1 and Word 2.
Joint: their joint frequency.
In line 2 of this display, PURSE occurs 6 times in the whole index, and STRINGS 5 times. They occur together 5 times -- in other words in this little corpus, strings is always part of the phrase purse strings. The gap is 1 because strings comes 1 word after purse. The pair purse strings comes in 3 texts.
As usual, the data can be sorted by clicking on the headers. Above, it was sorted by clicking on "MI" first and "Word 1" second.
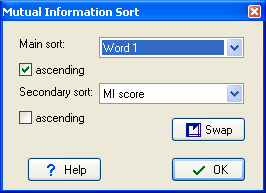
You get a double sort, main and secondary, because sometimes you will want to see how MI or Z score or other sorting affects the whole list and sometimes you will want to keep the words sorted alphabetically and only sort by MI or Z score within each word-type. Press Swap to switch the primary & secondary sorts.
Compare this with the display sorted by Z Score (Oakes p. 163).
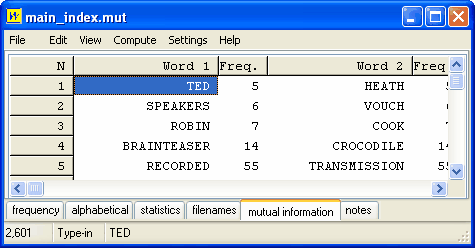
TED HEATH (a UK Prime Minister of the 1970s) is still top and SPEAKERS ... VOUCH still visible, but some other items have moved in.
Here is the display sorted by MI3 Score (Oakes p. 172):
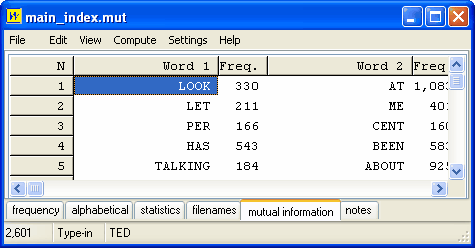
Much more frequent items have jumped to the top.
Finally, by Log Likelihood (Dunning, 1993):
Here the Word 2 items are very high frequency ones and we get at colligation (grammatical collocation).
See also: Formulae, Mutual Information, Computing Mutual Information, Making an Index List, Viewing Index Lists, WordList Help Contents.
See Oakes for further information about Mutual Information.