|
非用词词库/text> |

|

|

|
|
非用词词库/text> |
|
|
|
非用词词库是一个关于分析中不想被包含的单词列表。例如,你想建一个词表或者分析一些搜索词,但不想包含一些常见功能词语,例如the,of, was,,is, it。
使用 非用词词库, 首先准备一个文件,使用 记事本或者其它文字处理器, 标记出所有你想忽略的单词。 用逗号将每个单词分隔开,或者使它们各居一行。 你可以按照个人喜好使用大写字母或者小写字母标示。 可以在注释行用分号。 对字数没有限制。
有一个文件名为stop_wl.stp (在你的 \wsmith5 文件夹中)你可以直接保存在此文件名下,也可以另存为新的文件名。 或者你可以自己新建一个记事本文件,保存时以.stp 为文件拓展名。如果觉得这样有些困难可重命名.txt 为.stp。
举例
;我为测试建立的一个非用词词库 。
THE,THIS,IS
IT
WILL
然后在菜单项中选择 Stop List非用词词库 指定你想要使用的 stop list(s) 。各个非用词词库可以被用于 WordList,Concord 以及KeyWords程序中。 如果非用词词库被 激活,就会发挥作用:也就是,非用词词库中的词会在词表建立过程中被禁用。如果你想长期使用同一个或若个非用词词库你可以将其设置为wordsmith.ini格式 作为默认值。
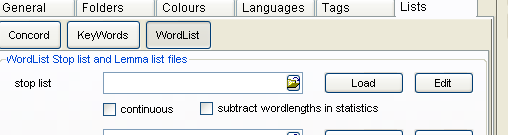
要选择非用词词库,点击截屏图案中的黄色小按键,找到非用词词库文件, 然后点击 Load载入。可以看到所找到列表的数目和部分列表。
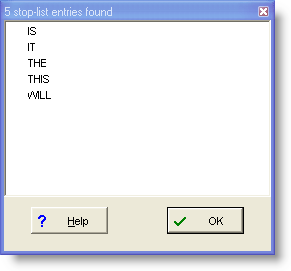
载入一个非用词词库之后,建立一个新的词表。非用词词库中的词是不会出现在新建词表上的。
continuous
正常情况下,在建立词表的过程中每个词都会被写入,并且储存在电脑存储器中,不经核对是否存在于非用词词库。 最终所写入的词会与你的非用词词库进行比对,禁用那些出现在非用词词库上的词。这样运行会更快一些。不过,大部分情况下, 所有 统计数据 都是在不考虑你的非用词词库前提下,基于全文本得到的。
如果你选择continuous持续 这个过程的速度就没明显放慢,因为每个单词被写入的时候都会与非用词词库进行比对,一旦吻合就会被禁用。换句话说, 每一次遇到 THE和 OF 以及 IS等都会被看作是要写入的文本内容,但是要在非用词词库中对其进行搜索。 这可以给你提供有关非用词词库中的词在词表中被禁用的详细统计数据。
subtract wordlengths in statistics在统计数据中缩短词长
如果你还没有选择上述的持续处理,你或许是想将词表统计结果的部分用非用词词表处理。这种情况下,在处理词表后,所有包含词型和词例数目、以及三个字母、四个字母单词等的词表都会按照整体数据列在统计信息中作调整(但不会调整单个文本的数据列)。
见: Match List 有更详尽的解释,并有截图说明。
另外一种建立非用词词表的方法是在大型语料库基础上采用 WordList ,如果只想得到高频率词,可将频率最小值设置为较大数字。然后将其另存为文本。之后,使用 文本转换器改变格式,用 stoplist.cod 文件作为 Conversion file转换规则文件。
参见: Making a Tag File, Match List, Lemmatisation.
Page url: http://www.lexically.net/wordsmith/step_by_step_Chinese/?proc_stop_lists.htm