Does it run on Windows 10, 11?
Yes. It needs Windows 10 or later.
For Apple Computers see Apple Macs or Linux with emulation.
Administrator rights
If you see a message saying something like "You need Administrator Rights to C:\program files\WSmith9\ for this" that is a general warning from Windows trying to protect you against viruses and malware. The Program Files folder is one Windows tries hard to protect.
Although in general program installation does go into Program Files, you may find it best to change the folder to eg. c:\wsmith9.
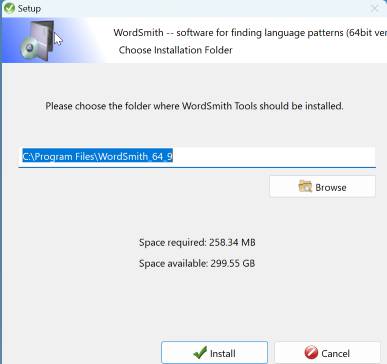
How to install on a network
Example of an installation for a site licence.
Online help.
Is there an important difference between a key word with a keyness of 50 and another of 500?
Suppose you process a text about a farmer growing 3 crops (wheat, oats and chick-peas) and suffering from 3 problems (rain, wind, drought). If each of these crops is equally important in the text, and each of the 3 problems takes one paragraph each to explain, the human reader may decide that all three crops are equally key and all three problems equally key. But in English these three crop-terms and weather-terms vary enormously in frequency (chick-peas and drought least frequent). WordSmith's KW analysis will necessarily give a higher keyness value to the rarer words. So it is generally unsafe to rely on the order of KWs in a KW list.
See also a presentation by Costas Gabrielatos and Anna Marchi which considers the whole issue of appropriate metrics for keyness.
How to process IPA phonetic symbols?
You will need to solve two quite separate problems.
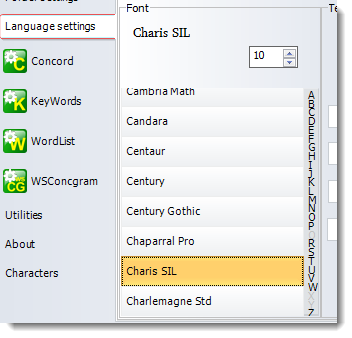
First, you need a suitable font in your computer to be able to see the symbols on the screen and print them. To do that, download a suitable font e.g. from SIL (CharisSIL) and ensure you copy all the .ttf files within it (CharisSILR.ttf, CharisSILB.ttf etc) to c:\windows\fonts.
Second, you need WordSmith to be able to process the symbols in your text files. The easiest way to do that is to ensure your texts are in Unicode (in MS Word, save as plain text (.txt) and in the set of encodings choose "Unicode"). Here's a zipped sample for you to use for test purposes.
You should now be able to open the unzipped sample text in Notepad, select your font and see everything OK. It should look something like this
Now re-start WordSmith so as to be sure all the fonts are loaded and choose the font in Language Settings :
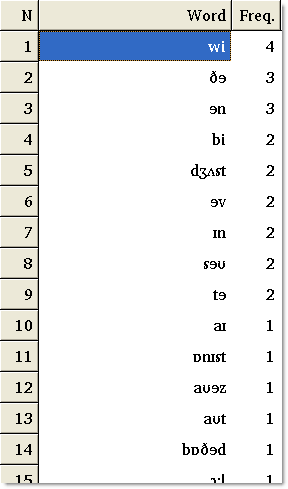
In the Characters window you should now be able to see the results. There are charts at Unicode e.g. here showing the IPA symbols.
With this you should now be able to generate a concordance:
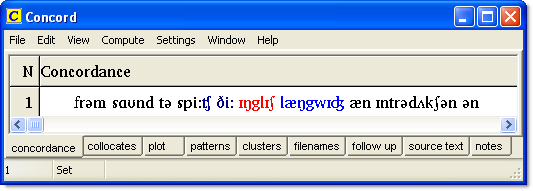
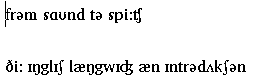
For a wordlist use : as an acceptable mid-word character and set the case to lower-case
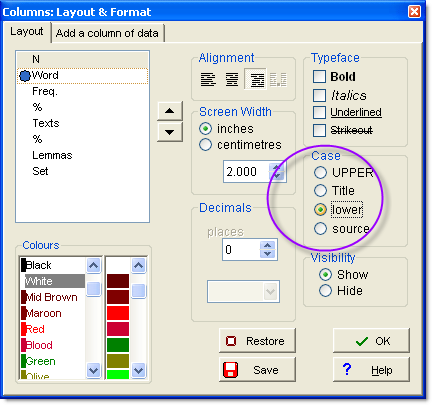
compatibility of files saved with different versions
As WordSmith develops, sometimes extra features need to be saved along with a word-list, a concordance etc. which were not saved in earlier versions. I try hard to ensure backward compatibility (e.g. that version 4 or 5 data can still be read OK using version 6, 7 or 8) but not forward compatibility. So reading version 6 data using a version 4 or version 5 copy of WordSmith may not work. Best solution -- keep up-to-date.
language choosing problems
Some users have reported problems choosing the language. If the Languages Chooser doesn't work or crashes, feel free to edit the plain text file language_choices.ini which you will find in the folder where your settings are stored (Documents\wsmith8). Edit the file using Notepad or similar, not Word. The file contains a number of references to languages. Try adding these and then saving.
[Chinese]
language name=Chinese
sort as in=2052
preference=alternative language
hyphen breaks word=NO
Windows codepage=936
Dos codepage=936
font name=Microsoft Sans Serif
font character set=136
font size=10
extra ANSI symbols within a word=
allow extra symbols at start of word=NO
allow extra symbols at end of word=NO
[Korean]
language name=Korean
sort as in=1042
preference=alternative language
hyphen breaks word=NO
Windows codepage=949
Dos codepage=949
font name=
font character set=130
font size=10
extra ANSI symbols within a word=
allow extra symbols at start of word=NO
allow extra symbols at end of word=NO
[Croatian]
language name=Croatian
sort as in=1050
preference=alternative language
hyphen breaks word=NO
Windows codepage=1250
Dos codepage=852
font name=Arial
font character set=238
font size=10
extra ANSI symbols within a word=
allow extra symbols at start of word=NO
allow extra symbols at end of word=NO
Actually all the languages chooser does is create / edit this plain text file.
After editing you will need to re-start WordSmith 7, and it will read the new version of your language_choices.ini file.
How to Update or Re-install
To update from an earlier version, please contact sales (at) lexically (dot) net giving details of your existing licence: you may be entitled to a 50% discount.
To un-install simply delete your Program Files\wsmith9 and Documents\wsmith9 folders. Alternatively, here is advice for a version which has got corrupted or to re-install afresh.
Registration problem?
The registration page tells me that the registration number is the wrong length. This is the registration number I had on my old computer:
Name: XXXX YYYY
Other Details:
Registration: SA00.1234.5678.9123.4567
WordSmith 4, WordSmith 5, WordSmith 6, 7 etc. each use different registrations. WordSmith publication dates started in 1996, WordSmith 6 in 2012, 7 in 2016, 8 in 2020, 9 in 2024. You can re-download your version from our site at any time. If you want to upgrade to the current version, please contact sales (at) lexically (dot) net giving details of your existing licence: you may be entitled to a 50% discount.
Converting PDFs
To convert PDFs to plain text can be extremely tricky even if you own a licenced copy of the Adobe software (Adobe themselves created the PDF format in 1993). That is because PDF is a representation of all the dots, colours, shapes and lines in a document, not a long string of words. It can be very hard with an image of the text, to determine the underlying words and sentences. A second problem is that PDFs can be set with security rights preventing any copying, printing, editing etc.
WordSmith's Text Converter has an option to attempt conversion to plain text: it succeeds with some PDFs but not all. Other methods are: to try to "select all" the text and then paste it into Word or Notepad.
In general, however, my advice is: do not collect a set of PDF documents hoping to use them as a corpus. Other formats (.TXT, .DOC, .DOCX, .XML, .HTML, .RTF etc.) are OK in principle as they do not contain only an image but also store within themselves the words and sentences.
How should texts be tagged?
WordSmith doesn't actually insert tag mark-up into your texts except in a way explained at http://www.lexically.net/downloads/version9/HTML/index.html?modify_source_texts.htm.
One way of getting your texts tagged is to use a tagger. Taggers are available for English and some other languages to insert Part of Speech (POS) mark-up into text quite reliably, or to mark up word meaning or syntax (less reliably).
In general if you want to type in your own mark-up my recommendations are:
use Notepad or similar (not Word) for the editing
use angle-brackets to mark start and end of tags as in <noun_plural>, <description>, <complaint>, etc.
use the switch-on/switch-off convention like this <complaint> .... </complaint> where </complaint> marks the end of the section of your text which you're calling a complaint.
if a tag needs no switch-off because it applies to one word only, put it just before the word it marks as in <noun_sing>elephant, <comparison>bigger, etc.