the point of it
You might want a word list based on some data you have obtained in the form of a list, but whose original texts you do not have access to.
requirements
Your text file can be in any language (select this before you make the list), and can be in Unicode or ASCII or ANSI, plain text.
<Tab> characters are expected to separate the columns of data. Decimal points and commas will be ignored. Words will have leading or trailing spaces trimmed off. The words do not need to be in frequency or alphabetical order. You need at least a column with words and another with a number representing each word's frequency.
example
; My word list for test purposes.
THIS |
67,543 |
IT |
33,218 |
WILL |
2,978 |
BE |
5,679 |
COMPLETE |
45 |
AND |
99,345 |
UTTER |
54 |
RUBBISH |
99 |
IS |
55,678 |
THE |
678,965 |
You should get results like these.
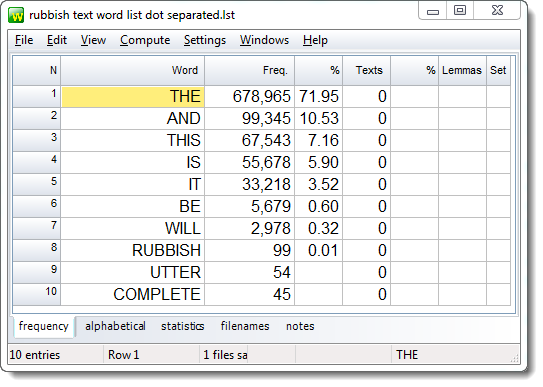
Statistics are calculated in the simplest possible way: the word-lengths (plus mean and standard deviation), and the number of types and tokens. Most procedures need to know the total number of running words (tokens) and the number of different word types so you should manage to use the word-list in KeyWords etc.
The total is computed by adding the frequencies of each word-type (67543+33218+2978 etc. in the example above).
Optionally, a line can start \TOTAL=\ and contain a numerical total, eg.
\TOTAL=\ 299981
In this case the total number of tokens will be assumed to be 299981, instead.
how to do it
When you choose the New menu option in WordList you get a window offering different tabs: choose Advanced,
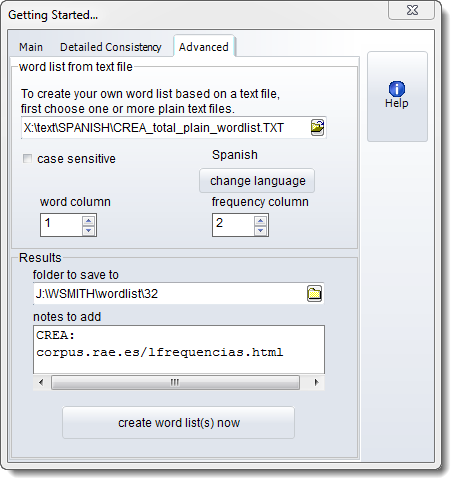
Choose your plain text list file and press import word list now.
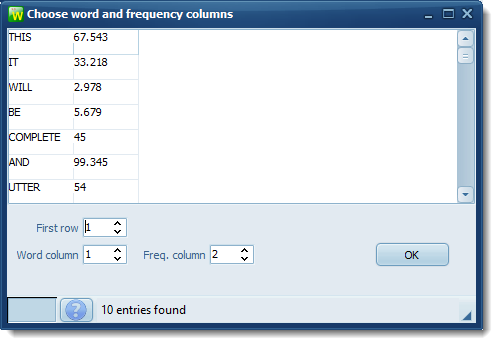
Set the word column and frequency column appropriately according to the tabs in each line.
If the list is all in lower-case forms you might need to convert the list to upper case for compatibility with WordSmith's default case insensitive lists. You can see the source form of your list using the Layout function. To convert to upper case use the menu option Edit | Capitalise.