Single words v. Clusters (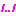 ) in WordList
) in WordList

Contents
WordList clusters
A word list doesn't need to be of single words. You can ask for a word list consisting of two, three, up to eight words on each line.
Example
Here is a small set of 3-4word clusters involving the word money.
Some of them are plausible multi-word units.
How to do it
To do cluster processing in WordList, first make an index.
Then open the index. Now choose Compute | Clusters.
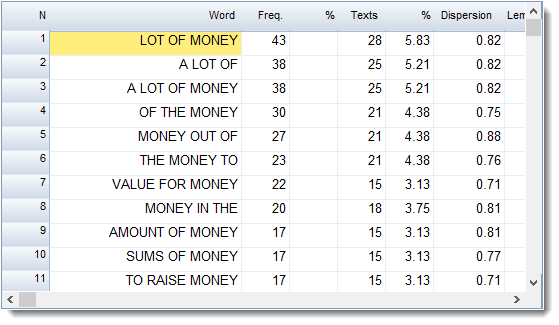
•"all" : all the clusters involving all words above a certain frequency (this will be slow for a big corpus like the BNC), or •"selection": clusters only for words you've selected (e.g. you have highlighted BOOK and BOOKS and you want clusters like book a table, in my book).
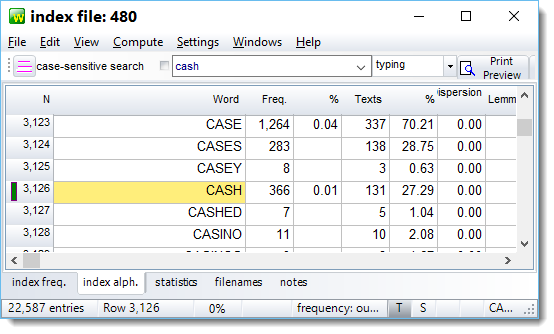
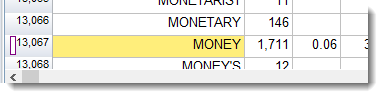
To choose words which aren't next to each other, press Control and click in the number at the left -- keep Control held down and click elsewhere. The first one clicked will go green and the others white. In the picture below, using an index of 480 texts, I selected cash and then money by clicking numbers 3,126 and 13,067.
The process will take time. . |
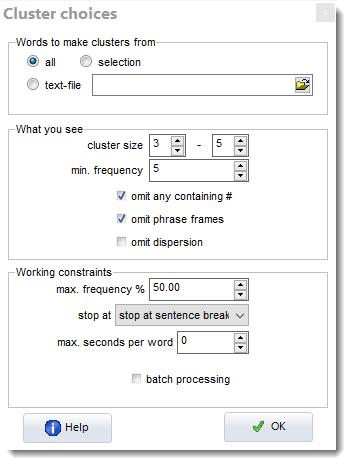
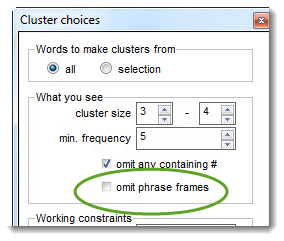
The cluster size must be between 2 and 8 words. The min. frequency is the minimum number of each that you want to see. omit #: if selected, this won't show any clusters involving numbers and dates omit phrase frames: see phrase frames section below. omit dispersion: if checked does not compute dispersion. Here the user has chosen to see any 3-4-word clusters that appear 5 or more times.
|
The "max. frequency %" setting is to speed the process up.
Stop at, like Concord clusters, offers a number of constraints, such as sentence and other punctuation-marked breaks. The idea is that a 5-word cluster which starts in one sentence and continues in the next is not likely to make much sense.
Max. seconds per word is another way of controlling how long the process will take. The default (0) means no limit. But if you set this e.g. to 30 then as WordList processes the words in order, as soon as one has taken 30 seconds no further clusters will be collected starting with that word.
batch processing allows you to create a whole set of cluster word-lists at one time.
|
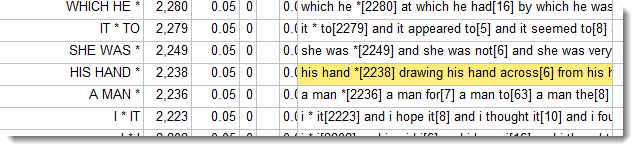
These are what William H. Fletcher has defined as phrase-frames, i.e. "groups of wordgrams identical but for a single word", in his kfNgram program.
Here, processing 23 Dickens novels shows lots of phrase frames where the wildcard word is represented with *.
If you double-click the lemmas column (highlighted here in yellow), you get to see the detail.
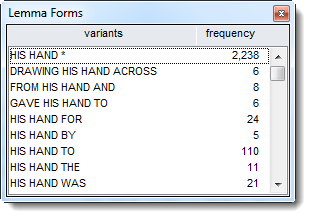
The process joins all the variants of the phrase in the Lemmas column. In the word list itself they will appear deleted (because they have been joined to another item, the phrase frame). You can un-join them all if you want (Edit | Joining | Unjoin or Unjoin all).
Omit phrase frames? If you don't want to see phrase frames, select the omit phrase frames option.
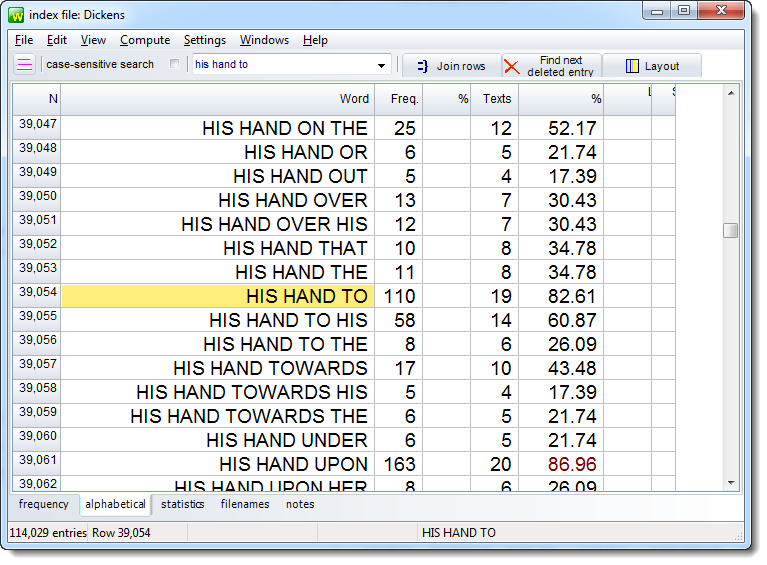
Here below, the listing has all his hand sequences together but not drawing his hand across, gave his hand to, etc. as shown in the phrase frame view above.
|
It's a word list
Finally, remember this listing is just like a single-word word list. You can save it as a .lst file and open it again at any time, separately from the index.
See also: find the files for specific clusters, clusters in Concord