WordSmith Controller KeyWords Settings

Contents
These are found in the main Controller marked KeyWords. 
This is because some of the choices may affect other Tools. KeyWords and WordList both use similar routines: KeyWords to calculate the key words of a text file, and WordList when comparing word-lists.
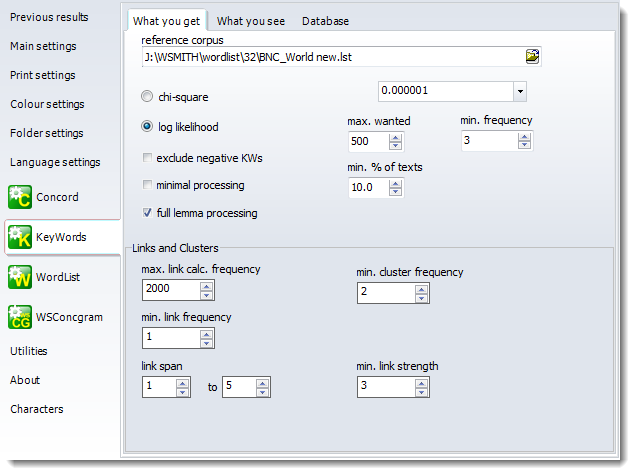
Procedure Chi-square or Log Likelihood. The default is Log Likelihood. See procedure for further details.
Max. p value The default level of significance. See p value for more details.
Max. wanted (500), Min. frequency (3), Min. % of texts (5%) You may want to restrict the number of key words (KWs) identified so as to find for example the ten most "key" for each text. The program will identify all the key words, sort them by key-ness, and then throw away any excess. It will thus favour positive key words over negative ones. The minimum frequency is a setting which will help to eliminate any words or clusters which are unusual but infrequent. For example, a proper noun such as the name of a village will usually be extremely infrequent in your reference corpus, and if mentioned only once in the text you're analysing, it is likely not to be "key". The default setting of 3 mentions as a minimum helps reduce spurious hits here. In the case of short texts, less than 600 words long, a minimum of 2 will automatically be used. The minimum percentage of texts (default = 5%) allows you to ignore words which are not found in many texts. Here the percentage is of the text files in the set you are comparing against a reference corpus. If you're comparing a word-list based on one text, each word in it will occur in 100% of the texts and thus won't get ignored. If you compare a word-list based on 200 texts against your reference corpus, the default of 5% would mean that only words which occur in at least 10 of those texts will be considered for keyness. The KeyWords display shows the number of texts each KW was found in. (If you see ?? that is because the data were computed before that facility came into WordSmith.)
Exclude negative KWs If this is checked, KeyWords will not compute negative key words (ones which occur significantly infrequently).
If this is checked, KeyWords will not compute plots, links or KW clusters as it computes the key words (they can always be computed later assuming you do not move or delete the original text files). This is useful if computing a lot of KW files in a batch, eg. to make a database.
Full lemma processing If this is checked (the default), KeyWords will compute the full frequency in the case of lemmatised items. For example if GO represents WENT, GOES etc. and GO alone had a frequency of 10 but the whole set GO, WENT, GONE etc. totalled 100, then its frequency will be counted as 100. If unchecked, GO would count only 10.
Max. link frequency To compute a plot is hard work as all the KWs have to be concordanced so as to work out where they crop up. To compute links between each KW is much harder work again and can take time especially if your KWs include some which occur thousands or hundreds of times in the text. To keep this process more manageable, you can set a default. Here 2000 means that any KW which occurs more than 2000 times in the text will not be used for computing links. (It will still appear in the plots and list of KWs, of course.) |
Columns The Columns to show/hide list offers all the standard columns: you may uncheck ones you normally do not wish to see. This will only affect newly computed KeyWords data: earlier data uses the column visibility, size, colours etc already saved. They can be altered using the Layout menu option at any time. |
Database: minimum frequency The default is 1. See database.
Database: associate minimum texts The default is 5. See associates.
|
See also: KeyWords Help Contents, KeyWords calculation.