|
Detailed Statistics (
|

|

|

|
|
Detailed Statistics (
|
|
|
|
Visible by clicking the Statistics tab at the bottom of a WordList window:
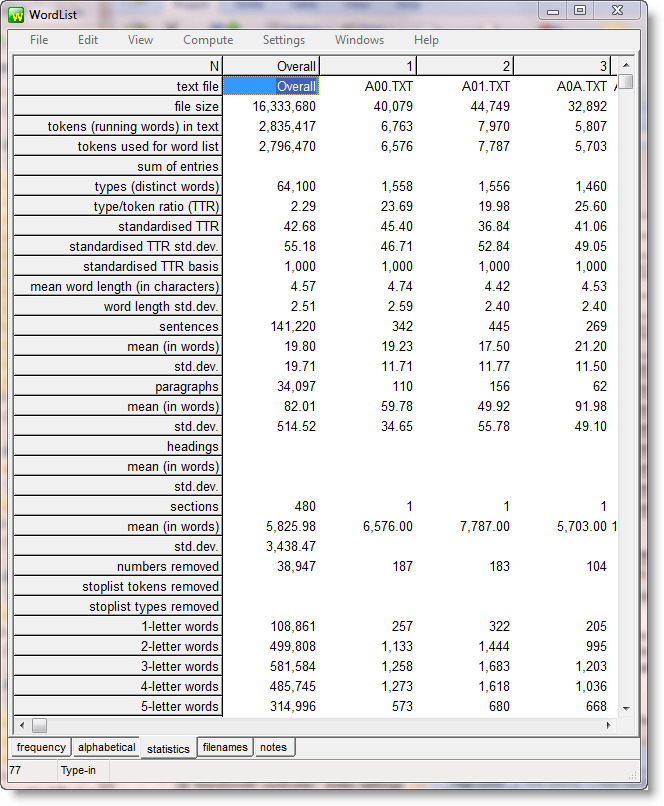
The overall results are in the left column, and details for the individual text files follow in columns to the right. In the screenshot you can see that the average sentence length of the 480 texts overall is 19.80 words, while that of text A01.txt is 17.5.
Statistics include:
number of files involved in the word-list
file size (in bytes, i.e. characters)
running words in the text (tokens)
tokens used in the list (would be affected by using a stoplist or changes to minimum settings)
sum of entries: choose Compute | Tokens to see, otherwise this will be blank
no. of different words (types)
no. of sentences in the text
mean sentence length (in words)
standard deviation of sentence length (in words)
no. of paragraphs in the text
mean paragraph length (in words)
standard deviation of paragraph length (in words)
no. of headings in the text (none here because WordSmith didn't know how to recognise headings)
mean heading length (in words)
no. of sections in the text (here 480 because WordSmith only noticed 1 section per text)
mean section length (in words)
standard deviation of heading length (in words)
numbers removed
stoplist tokens and types removed
the number of 1-letter words
...
the number of n-letter words (to see these scroll the list box down)
(14 is the default maximum word length. But you can set it to any length up to 50 letters in Word List Settings, in the Settings menu.) Longer words are cut short but this is indicated with a + at the end of the word.
The number of types (different words) is computed separately for each text. Therefore if you have done a single word-list involving more than one text, summing the number of types for each text will not give the same total as the number of types over the whole collection.
Sum of entries
In the display, the sum of entries row shows the total number of tokens by adding the frequencies of each entry. In these data, there were over 2.8 million running words of text, but 38,947 numbers were not listed separately, so the number of tokens in the word-list is a little under 2.8 million.


Sum of entries was computed after the word-list was first created by choosing Compute | Tokens
See also : WordList display (with a screenshot), Summary Statistics, Starts and Ends of Text Segments, Recomputing tokens.
Page url: http://www.lexically.net/downloads/version5/HTML/?stats.htm

