|
Follow-up concordance searches ( |

|

|

|
|
Follow-up concordance searches ( |
|
|
|
The point of it...
The idea is to follow up a large concordance by breaking it down into specific sub-sections, so one can see how many of each sub-type are found in the whole list.
Example
The screenshot below came from a concordance of beautiful in Charles Dickens:
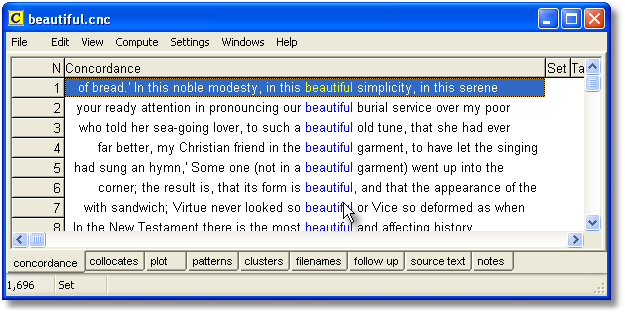
There are 1,696 lines. Looking through them, it became apparent that Dickens was fond of the collocations beautiful creature and beautiful face, but how many are of beautiful creature and what proportion of the 1,696 is that?
"Follow-up" does this. Here, as well as the main follow-up tab below, we see two tabs at the top showing the percentage of the overall 1,696 lines which have beautiful creature and beautiful face.
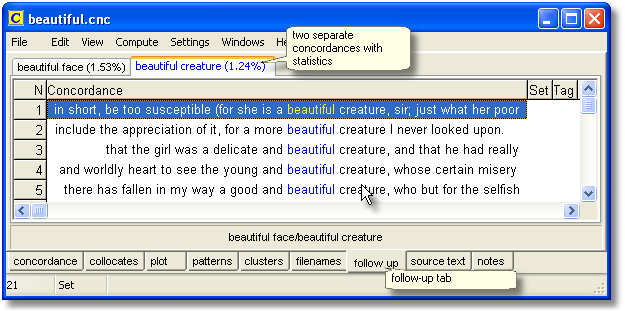
Beautiful creature represents 24 lines, which is 1.24% of the whole set. Beautiful face takes up 1.53%.
How to do it
In the Compute menu, choose Follow. In the dialogue
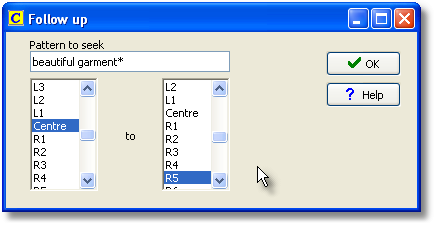
type in your search requirement (for beautiful creature and beautiful face I typed beautiful creature/beautiful face) and choose the search-horizons.
Page url: http://www.lexically.net/downloads/version5/HTML/?conc_follow_up.htm

