|
Collocation Relationship |

|

|

|
|
Collocation Relationship |
|
|
|
The point of it...
The idea is to find out how strongly each collocate relates to the search-word near which it was found. MI (or other relevant statistic) is not computed by default for a collocate list.
How to compute it
In the Concord menu, choose Compute | Relationships:
Steps
| 1. | Suppose you have made a concordance using all the files in Documents\wsmith5\text\shakespeare and have done a concordance on love. You see collocates such as Romeo, hate, the, Juliet, Nurse etc. All these show a "Relation" score of "??" because they haven't yet been computed. |
| 2. | If you haven't done so yet, use WordList to make a word list of the same text files (or if you prefer, use some other reference corpus). Make sure the reference corpus file is what you prefer. |
| 3. | Now choose the menu item |
You can choose a different statistic in the main Controller Concord settings.
Note: if one of your search-terms has a space in it such as Friar Lawrence, an ordinary single-word word list won't know its frequency and you will be asked to supply it. If you don't know, you should compute a concordance on that search-phrase over the same corpus first.
Full lemma processing, case sensitive
These should be checked if your word list has any lemmatised entries, or it is a case-sensitive word list.
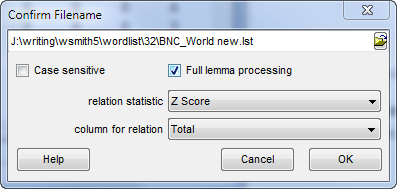
Relation statistic
Choose which type of relation you wish to compute. The default is Specific Mutual Information but in the screenshot Z score has been chosen.
Column for relation
The default is "Total" but you can choose some other column's data: 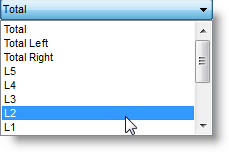
See also: Collocation, Collocate display, Mutual Information
Page url: http://www.lexically.net/downloads/version5/HTML/?collocationrelationship.htm

