|
WordSmith controller: Index settings |

|

|

|
|
WordSmith controller: Index settings |
|
|
|
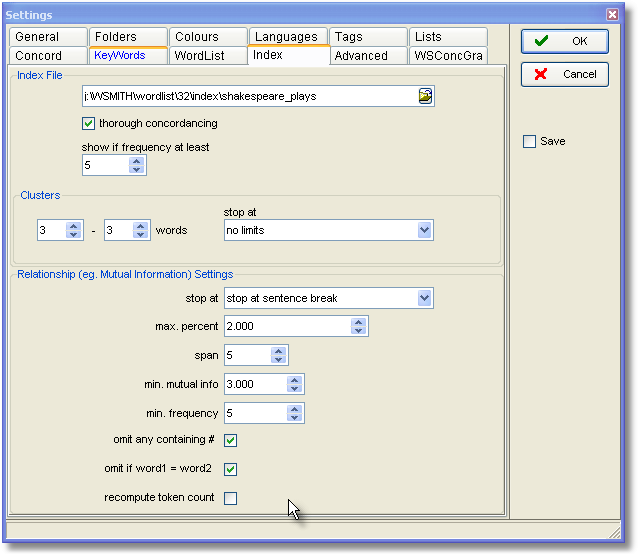
Index File
The filename is for a default index which you wish to consider the usual one to open.
thorough concordancing: when you compute a concordance from an index, you will either get (thorough checked) or not get (if not checked) full sentence, paragraph and other statistics as in a normal concordance search. (Computing these statistics takes a little longer.)
show if frequency at least: determines which items you will see when you load up the index file. (What you see looks like a word list but it is reading the underlying index.)
Clusters
the minimum and maximum sizes are 2 and 8. Set these before you compute a multi-word word list based on the index. A good maximum is probably 5 or 6.
stop at: you can choose where you want cluster breaks to be assumed. With the setting above (no limits), "I wrote the letter. Then I posted it" would consider letter then I posted as a possible multi-word string even though there's a sentence break between them.
Relationship settings
stop at: you can choose where you want collocational breaks to be assumed. With the setting above for relationships (stop at sentence break), "I wrote the letter. Then I posted it" would not consider posted as a possible collocate of letter because there's a sentence break between them.
max. percent: ignores any tokens which are more frequent than the percentage indicated. (The point of this is to avoid computing mutual information for words like the and of, which are likely to have a frequency greater than say 1.0%.)
span: the number of intervening words between collocate and node. With a span of 5, the node wrote would consider the, letter, then, I and posted as possible collocates if stop at were set at no limits.
min. mutual info: the minimum number which the MI or other selected statistic must come up with to be reported. A useful limit for MI is 3.0. Below this, the linkage between node and collocate is likely to be rather tenuous.
min. frequency: the minimum frequency for any item to be considered for the calculation (default = 5). (If an item occurs only once or twice, the relationship is unlikely to be informative.)
omit any containing #: disregard numbers
omit if word1 = word2: disregard cases like happy .. happy where a word collocates with itself
Page url: http://www.lexically.net/wordsmith/step_by_step_Chinese/?wordsmith_controller_index_set.htm

