|
relationships computing |

|

|

|
|
relationships computing |
|
|
|
In WordList or in Concord
MI (or other relevant statistic) is not computed by default for a collocate list. To compute the statistic you want, you need a word list to supply the relevant data. Steps
You can choose a different statistic in the main Controller Concord settings.
|
To compute all these relationship statistics you need a WordList Index. Call up the alphabetical view of the list. When you press If you wish to select only a few items for MI calculation, you can mark them first (with
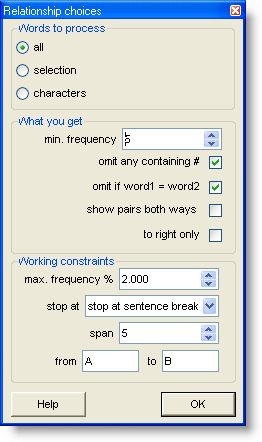
What you get: set the minimum frequency to suit the frequency, e.g. 5 means that no word of frequency 4 or less in the index will be visible in the MI results. Omit any containing # will cut out numbers, and omit if word1=word2 is there because you might find that GOOD is related to GOOD if there are lots of cases where these 2 are found near each other. Show pairs both ways allows you to locate all the pairs more easily because it doubles up the list. For example, suppose we have a pair of words such as HEAVEN and EARTH. This will normally enter the list only in one order, let us say HEAVEN as word 1 and EARTH as word 2. If you're looking at all the words in the Word 1 column, you will not find EARTH. If you want to be able to see the pair as both HEAVEN - EARTH and EARTH - HEAVEN, select show pairs both ways.
To right only: if this is checked, possible relations are computed to the right of the node only. That is, when considering DUST, say, cases of WITH to the right will be noticed but cases where WITH is to the left of DUST would get ignored.
Here, the number of texts goes down to 5 from 9, MI score is lower, etc, because the process looks only to the right. (In the case of a right-to-left language like Arabic, the processing is still of the words following the node word.)
Working constraints: this is to set things so that the process doesn't take forever, as explained below. Stop at has to do with whether breaks such as punctuation or sentence breaks determine that one word cannot be related to another; to suit the frequency, e.g. 5 means that no word of frequency 4 or less in the index will be used in the MI results. Span is how far left and right to look for the MI relation. A span of 5 means, for example, from the node word forward to R4 position, inclusive. From A to A lets you choose a range of words starting with those characters. You can always do part of the list (eg. A to D) and later merge your mutual-information list with another (E to H).
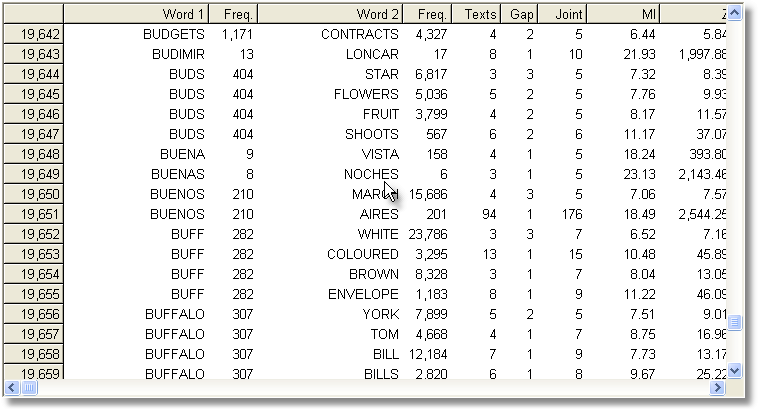
Computing the MI score for each and every entry in an index takes a long time: it took over an hour to compute MI for all words beginning with B in the case of the BNC World edition (written, 90 million words) in the screenshot below, using the settings visible above. It might take 24 hours to process the whole BNC, 100 million words, even on a modern powerful PC. Don't forget to save your results afterwards!
|
See also Collocates, Mutual Information Settings, Mutual Information Display, Detailed Consistency Relations, Making an Index List, Viewing Index Lists, Recompute Token Count, WordList Help Contents.
Page url: http://www.lexically.net/wordsmith/step_by_step_Chinese/?proc_mutual_information_comput.htm


.png)
.png)