|
计算数据频率 |

|

|

|
|
计算数据频率 |
|
|
|
你也许想知道你的索引行中有多少行包含"happi*"或者一个词表中有多少词条的词尾是 *ly。 要知道这些, 选择 Summary Statistics in the Compute menu.
Example
你已经计算了一个词条。 在索引行中任意选择一处然后选择Compute : Summary Statistics。 在搜索框里输入happi* 和 love。
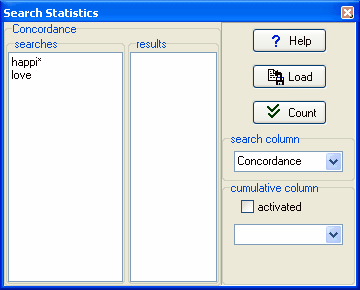
点击 Count -- 你应该看到如下信息:
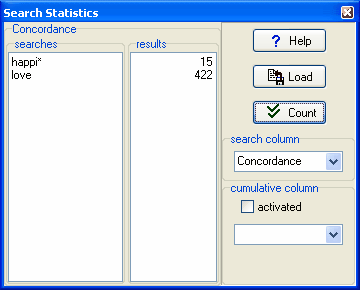
这一步骤已经对你所有的索引行进行了处理并且找出了15条含有happi* 以及 422 条含有整个单词 love (不包括loved, loves)。
Search 栏
这个组合框让你选择哪一拦的数据需要计算在内。
Cumulative 栏
累积计算是在你处理搜索数据以外的另一个数据框里合计频数。 这个组合框里的每一栏里都只能是数字数据。 选定一个并确定 activated已经勾选。
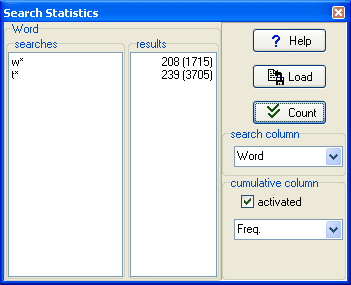
在此例中, 我们计算了一个词表并研究了首字母是 W 或T。 其中有208 条首字母是 W。 在括号中你可以看到1715 -- 这表示累计计算首字母是 W的词的频率(Freq.column)是1715也就是说平均频率约为8 (1715 / 208)。 但是对于首字母是 T, 尽管绝对数很相近(239), 但是它的平均累积频率约为15。 这是因为英语中有很多高频词的首字母是 T。
Load
你可以在搜索窗口中录入你已经提前准备好的任何 纯文本 文件。
参见:计算新数据栏。
Page url: http://www.lexically.net/wordsmith/step_by_step_Chinese/?countdatafrequencies.htm