This information was kindly supplied by Liu Patric <patric_lx@yahoo.com.cn>.
wordsmith4 是一套很出色的多语种的功能强大的语言检索软件。基于我对汉语检索
方面的一点实践经验 , 现在就如何利用 wordsmith4 检索汉语数据文本做一点介绍。
有不到之处 , 还请批评指正。
在使用 wordsmith4 之前必须注意以下几点:
1 .待检索的数据文本是否是以 Unicode 编码的纯文本文件 : wordsmith4 在处理数据文本时 , 要求数据文本是以 Unicode 编码的 .txt 纯文本文件 , 但是现代汉语数据文本是以 GB2312 编码的,为什么这样?我还说不清楚。请原谅我不是计算机高手。所以你得把你的文本文件转换成纯文本文件。如何转换呢?我介绍完下面一个重要的步骤再具体说明。
2 .除了要求是纯文本文件之外,还得要求纯文本里的汉字之间有空格 。我们发现文本里的汉字之间是没有空格的,这和英语是不同的,英语每个单词之间是有空格的。那怎么办呢?也就是要求在汉字之间插入空格。
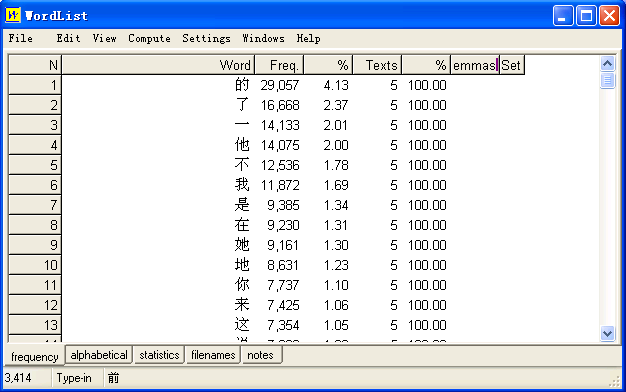
3 .但是如果我们在所有的汉字之间插入空格,那在进行 WORDLIST 处理的时候,我们看到的肯定是一份“单字”表了。而没有诸如“如果”的词语了。
4 .利用中科院的 ICTCLAS 对汉语文本进行分词处理 。后来我在使用中科院的 ICTCLAS (汉语文本词性标注标记工具)对汉语纯文本进行处理的时候,发现这个软件在进行分词处理的同时,也就在字词之间同时加入了空格。(为了加空格的问题,我还特意请我的一位朋友给我写了小小的程序,现在看来似乎不需要了。)但是请注意, ICTCLAS 直接处理以 GB2312 编码的纯中文文本,而且生成的 _cla 文本文件仍然是以 GB2312 编码的。
5 。文本编码转换的问题 。可喜的是最新版的 WS4 已经改进了强大的转换功能。( Utilities-Text converter-conversion-into Unicode based on-Chinese PRC 2312 )
6 .语言设置成“ Chinese”. 具体设置: settings-Adjust settings-Text & languages-Edit languages-Main-select Chinese PRC
7. 所有汉语文本转换成 Unicode 编码之后,现在就可以利用 wordsmith4 进行检索了。
WordSmith needs Chinese to be in plain text, in Unicode and with spaces between groups of characters. To insert spaces appropriately, use ICTCLAS (Institute of Computing Technology, Chinese Lexical Analysis System, designed by the Chinese Academy of Social Sciences); demos can be downloaded from their website: http://ictclas.nlpir.org/downloads or http://ictclas.nlpir.org/online. There is a copy of the free version (1.0) of their software here.
In order to concordance a Chinese phrase like “ 但是 ”, ICTCLAS will preprocess the texts by lexiparsing the original texts.
This screenshot shows what your text will be like:
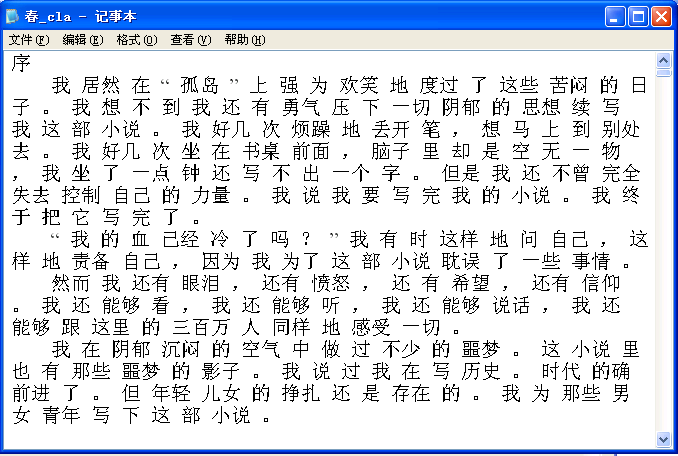
Then we can concordance “ 但是 ”
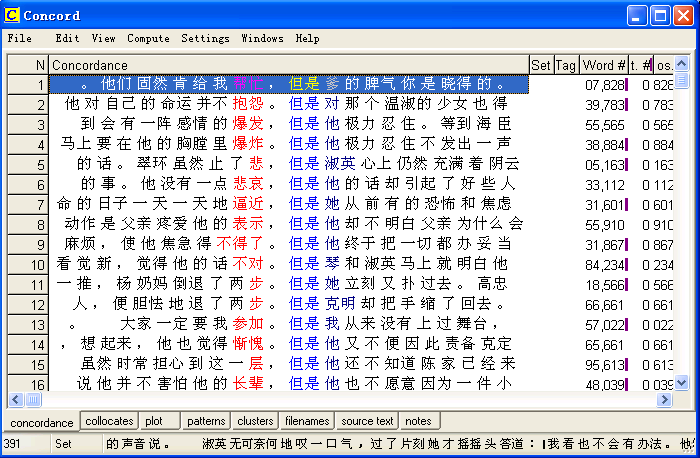
And we can get a reasonable wordlist:
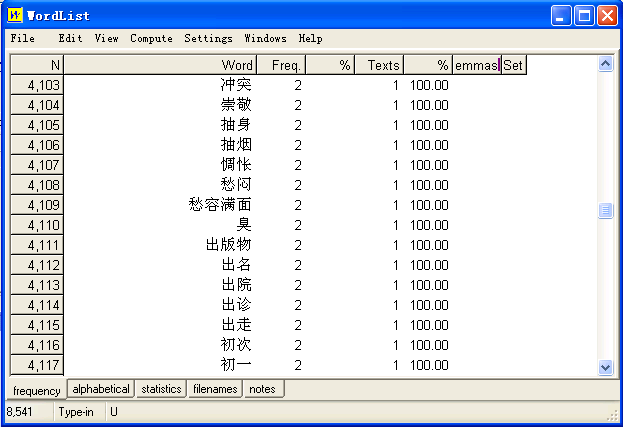
If you do not use ICTCLAS, you will get results like this with Concord.
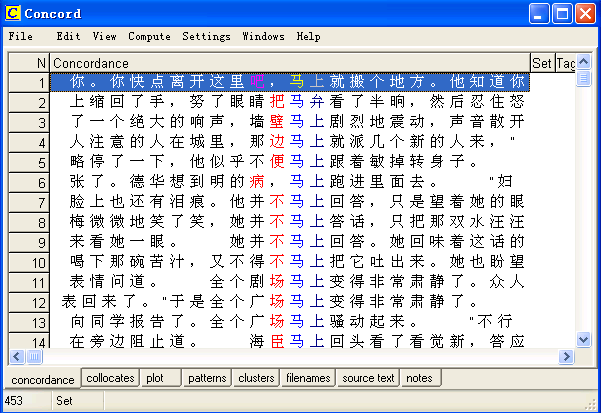
and in WordList: