The point of it
The idea (suggested by André Luiz Siqueira Alencar) is to generate a detailed list showing which tags were found how many times in each of the text files of your corpus.
How to do it
The function requires the WordList tool. Choose a set of texts and ensure you have loaded a tag file.
Now choose the Tag recording tab and select a suitable file-name. Ensure you have the save tag usage list box checked.
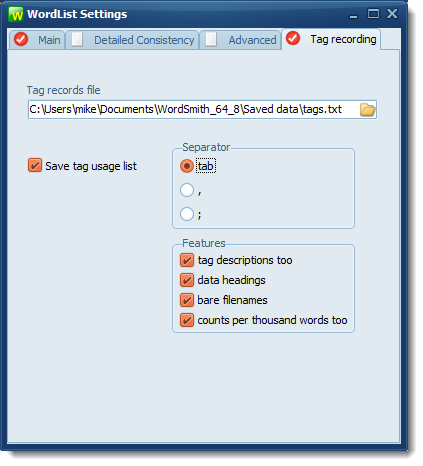
Settings
Choose separator, a character which will appear between each column of output. Tab, comma, or semi-colon.
Features:
If your tags have descriptions you can get these listed too.
Optional headings will tell you whether the data has both raw counts and per-thousand-word counts.
The data for each text file:
Bare filenames: if this is checked you just see the filename without its path.
Counts per 1000 -- check this if you want that as well as the raw data for each text file.
Now return to the Main tab and press Make a word list now.
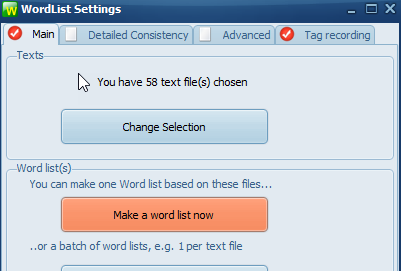
WordList will generate a word list in the usual way as in this example:
and open up the saved plain text file your specified showing your results.
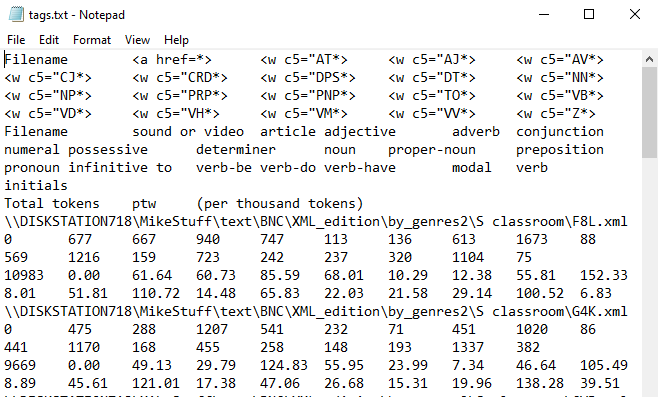
It will be much easier to handle and appreciate if you simply open this up instead with Excel:
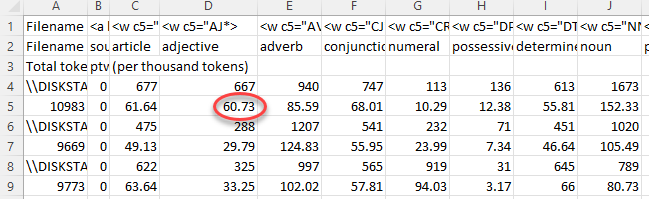
The top lines show the tags as you defined them and descriptions if applicable. Following lines give the number found for each text file. In these data none of the text files had sound tags, but they all had a mix of the other tags. The row below the file-name row shows in the left column the total tokens, then for each tag its frequency per thousand tokens. So in these data, the first text file has 10,983 tokens, and 667 marked as adjectives. That is 60.73 adjectives per 1,000 tokens.