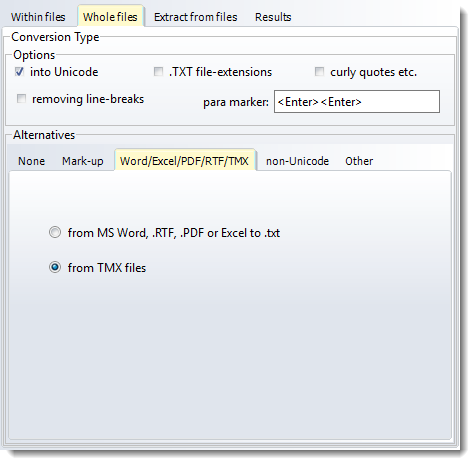
 from MS Word, Excel, PDF or RTF to .txt
from MS Word, Excel, PDF or RTF to .txt
This is like using "Save as Text" in Word or Excel. Handles .doc, .docx (Office 2007) and .xls or .xlsx files.
Not guaranteed to work with all .RTF texts but should indicate whether the conversion is or is not successful.
Here is what happens when some conversions fail:
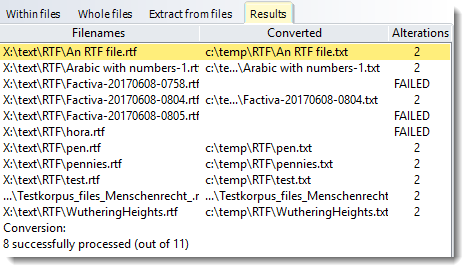
Any which fail you may be able to use the latest version of MS Word to save as text.
|
from PDF
Not guaranteed to work with every .PDF as formats have changed and some are complex.
To convert PDFs to plain text can be extremely tricky even if you own a licensed copy of the Adobe software (Adobe themselves created the PDF format in 1993). That is because PDF is a representation of all the dots, colours, shapes and lines in a document, not a long string of words. It can be very hard with an image of the text, to determine the underlying words and sentences. A second problem is that PDFs can be set with security rights preventing any copying, printing, editing etc.
|
from TMX
TMX files are translation memory files where one file contains aligned text in more than one language. The idea is to extract the text of the translations in the different languages and save them as separate plain text files.
Example
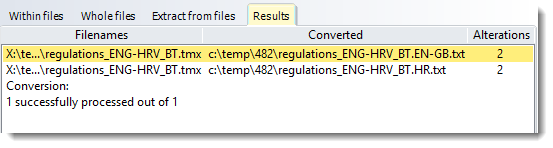
Here one .TMX file has had two texts extracted from it, one in English ending EN-GB.txt and the other in Croatian ending HR.txt. Both are plain text.
|
See also: Convert Entire Texts