WordSmith Tools Help
The idea here is to mark up your corpus with clusters or phrases you want treated as single items.
You can do that in 2 ways:
•insert _ so Los Angeles becomes Los_Angeles and New York = New_York (top box)
and/or
•annotate the text so Los Angeles becomes <mwu>Los Angeles</mwu>. (lower box)
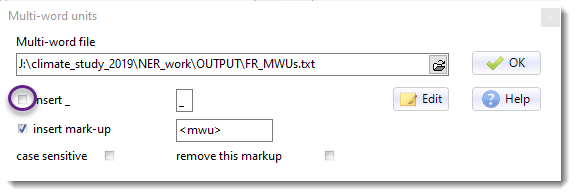
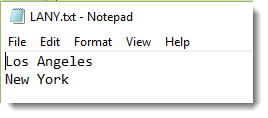
For either method you'll need a phrase file which contains the items you're interested in. Mine contained just this:
After processing (using the tag insertion method) my source text looked like this:
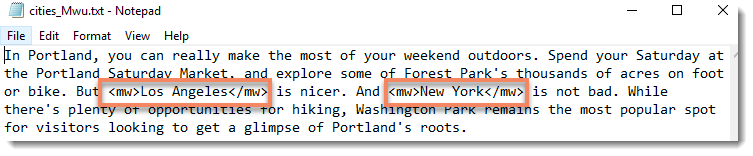
with <mwu> before and </mwu> after each item found.
Whole word search
The search is a whole word search. It will find New York in ... New York's people but not in that's very New Yorkish ....
Case sensitivity
Whether you choose case insensitive or sensitive only determines whether the search succeeds or fails. (If your phrase file has new york then a case insensitive search will also find New York, new York or New york.)
Replacement
Replacements will match the case in the original text file.
Original: New York people ... they were in a new York restaurant ...
Conversion: <mwu>New York</mwu> people ... they were in a <mwu>new York</mwu> restaurant ...
Handling the text now it has been modified
With method 1, you merely need to teach WordSmith that the underscore character is to be accepted as a valid character.
With method 2, you merely have to let WordSmith handle your mark-up to make a word list with clusters in single-word list.
Made a mistake?
Run the procedure again with the same texts and list of multi-word items but choosing remove this markup.