
The aim is to create a lemma file using a corpus which has lemmas marked up.
Example
The BNC XML edition uses mark-up like this:
.... <w c5="AJC" hw="strong" pos="ADJ">stronger </w> .....
where the lemma (head-word) is strong but the word in context is stronger. You can use the lemma file building procedure to go through all the .xml texts in this corpus finding all the items which are marked as belonging to the same lemma (members of the lemma) and saving them in a text file.
How to do it
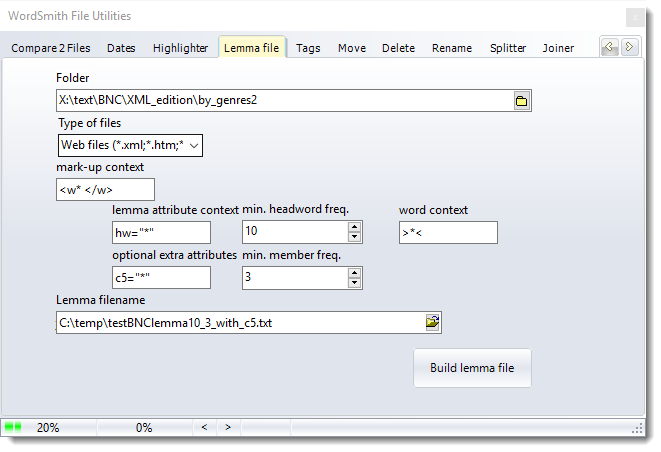
Folder and files
Choose a folder which the corpus is headed by.This and any sub-folders will be searched for your corpus files (such as .xml).
Mark-up context
In the mark-up context you need to specify the start and end of each chunk of your corpus which will contain both a lemma (head-word) and an original word. The asterisk is used to represent a whole lot of characters including spaces, so for the example given above <w* </w> as seen in the picture is sufficient to find the mark-up, because each relevant chunk starts with <w and ends with </w>. Within that mark-up, the lemma attribute can be found by searching for hw="*". (The * in this example would pick out the head-word strong.) And the word context can be defined as >*<, in other words the word stronger will be after a > and it'll run up to the following <.
Optional extra attributes
This lets you get results like
ACCOMMODATE -> <VVI>ACCOMMODATE,<VVN>ACCOMMODATED
In the screen-shot above, I specified the c5 attribute, which in the case of accommodate picked up the VVI and the VVN attributes as well as the word-forms. Leave blank if not wanted.
Minimum frequencies
This setting lets you filter out infrequent variants such as these:
ABBOTSONIAN -> ABBOTSONIANS
ACH -> ACHES
ADUMBRATE -> ADUMBRATED
The picture above shows a minimum of 10 occurrences required in the corpus for each lemma, with a minimum number of 3 members, probably more useful for a corpus of 100 million words.
Once you fill in the details and press Build lemma file, the process will run until it completes the task. The result will be a lemma file which may be useful in filtering word lists. Note that the accuracy of the list will depend on the BNC's own parsing in the first place, so you may find HAVEING as a lemma variant of HAVE, BES as a variant of BE, so the list will benefit from manual checking, especially if you set a minimum frequency of 1 for members of each lemma.
