
The point of it
The idea as explained by Egbert and Biber (2019) is to help in the study not of single texts but of sub-corpora of text. They argue that text dispersion key words are more representative of the sub-corpus as a whole.
How to do it
In the Controller settings, check the text dispersion box.
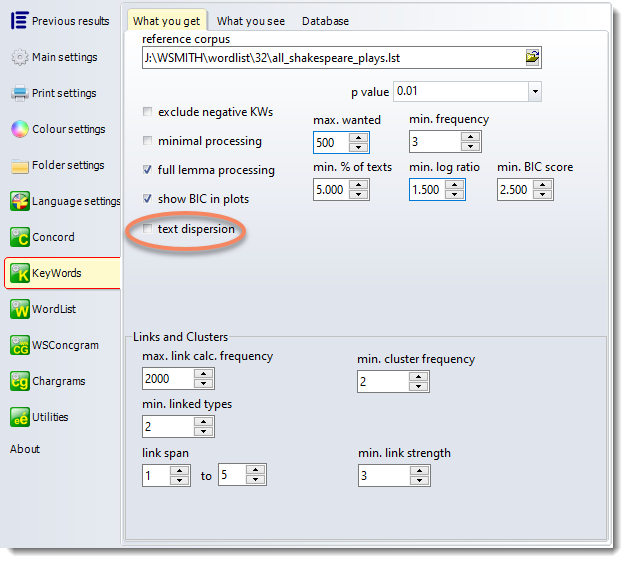
Choose your sub-corpus and reference corpus files, remembering that what will count is the number of texts each word is found in.
Example
This was computed using the 24 BNC written academic medicine texts. The reference corpus was the whole BNC XML edition.
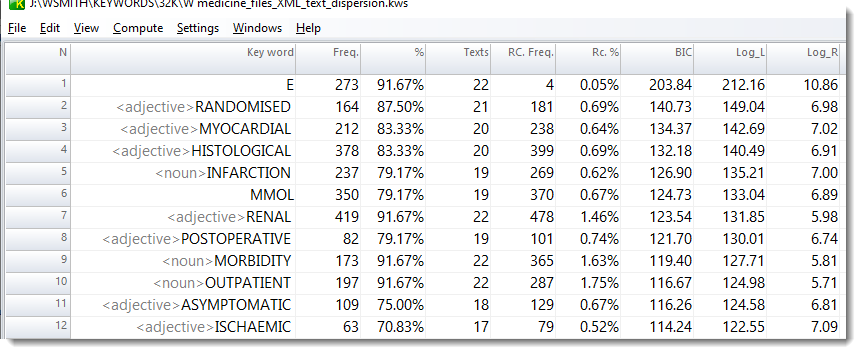
Percentage columns
In the case of text dispersion key words displays, the Freq. column (as before) shows the token frequency of each key word. The % column now gives the percentage of texts that KW was found in (here a total of 24). The Texts column is as before. The RC % column shows the percentage of the number of texts each KW was found in.
Results below were derived from the 44 commerce texts:
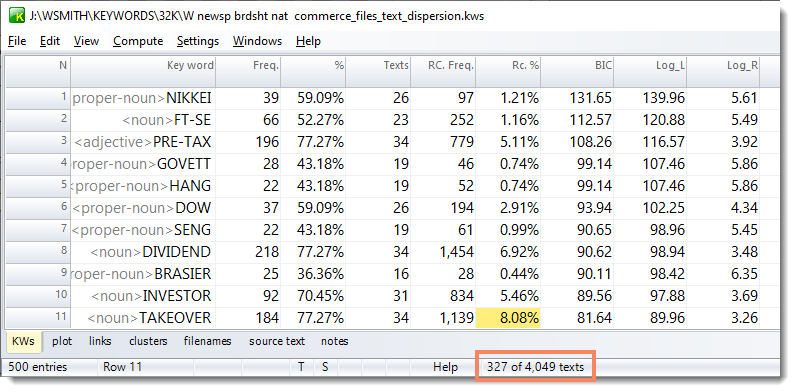
TAKEOVER was found in 34 of 44 commerce texts (77.27%) and the 8.08% represents 327 of the 4,049 reference corpus texts as shown in the status bar.
