
The point of it
News texts are often edited slightly and re-published a few days later or in a sister publication.
The idea is to be able to check whether you have virtually duplicate text files, i.e. with the same or similar contents. This search compares all text files with each other regardless of their file-names. If duplicates are found you can move and rename them so they can be avoided in further research.
How to do it
Specify your Folder to search and file-type(s). Check the difference settings, then simply press "Search". Search will go through that folder and any sub-folders and will report any duplicates found. Note: it will take time, as it needs to compare each text file with all the others in those folders. The comparison checks the vocabulary used in each pair of texts.
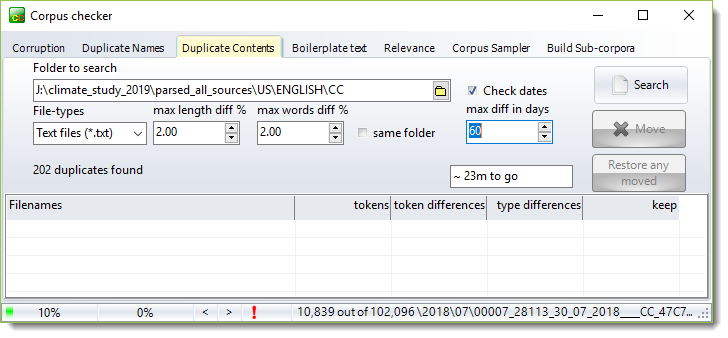
Here the status bar shows there were over 80,000 text files, 20% have been checked and 3,460 originals with their near-duplicates found. The remaining time is estimated at 16 minutes.
Settings
An intrinsically slow process can be speeded up by reducing the number of text files which get compared with each other.
Max length diff = how much difference in length will you accept in a comparison? The bigger any length differences the slower the process. In the case above a setting of 2.0% was used, so any a text of exactly 100Kb in size would only get compared with others between 98 and 102Kb in size.
Max words diff = how much difference in types or tokens will you allow and still consider the texts duplicates?
Check dates: if this is selected, you can decide how many days apart text files can be.
Same folder: if this is checked, only text files in the same folder get compared. In the study above that meant only texts of the same month got compared.
Pause the process? Well, you can stop it (press the red exclamation mark). To re-start at a specific point, hold down Ctrl as you press the Search button and you can re-start at 25% or wherever you wish.
Example

The highlighted line shows two text files within 4% difference in date and size and with contents which matched in word types and word token counts within 4%. Both from the same paper, 1st August 2011, 29 token differences.
At the right you can see a keep column, where by default one of the two text files is marked for deletion (see Remove below).
Right-clicking and choosing Show reveals minor differences in any two or more texts:
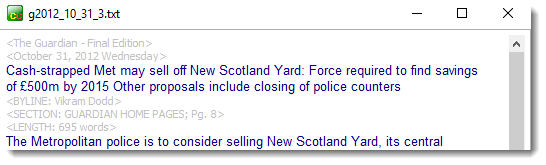
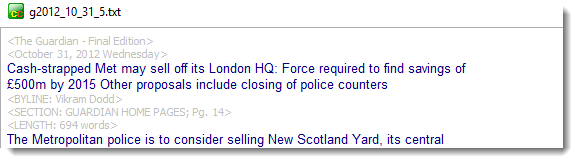
Right-clicking the latter window and choosing Highlight similarities gave this:
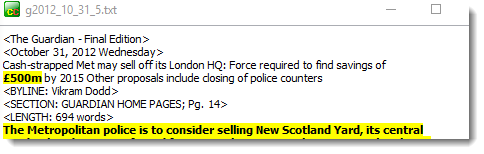
Angle-bracketed lines are not compared. In the rest of the text, identical lines get coloured yellow. Most of the rest of the text is coloured yellow. Here what has happened is that an editor has changed New Scotland Yard to its London HQ. It looks as if minor edits were performed but otherwise text 3 and 5 are duplicates.
Copy, Move, Show, Keep
When the search finishes you can press Move to filter duplicates to a moved sub-folder. Use the Restore any moved button to go through all the set, putting any moved back where they belong. (You may have to close the Corpus Checker first.)
Right-clicking the display of duplicate files gives these options:
To view, choose Show in the right-click menu. Or double-click to open any file in Notepad. Copy produces a list of the results which you can paste elsewhere. Remove simply moves all the duplicates which are marked for deletion, to a sub-folder of where they were before, called "moved". To change which duplicate is kept, select the one you do want and press Keep.
 How does it check duplication?
How does it check duplication?
See also: duplicate file-names
