
The point of it...
The idea is to follow up a set of associates by identifying the texts which are most closely related to the topic it suggests.
How to do it
in a list of associates, choose the follow-up menu item.
Example
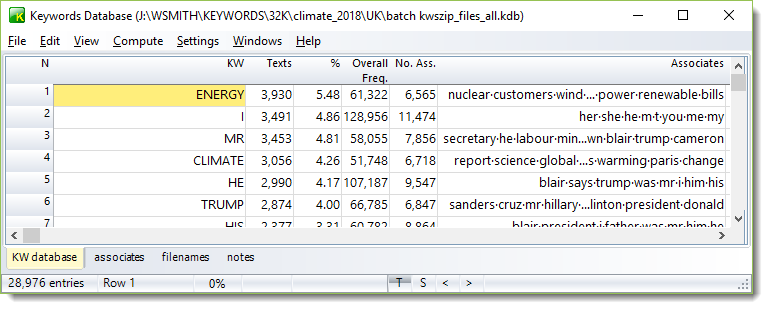
Here, a study on climate change texts has climate as one of its key key words. Among the 75,000 source texts, some mention climate change only incidentally and I wanted to restrict the corpus by about half, separating out such texts. (For another purpose one might want to study only those texts of course.)
A first step is to identify the associates of climate.
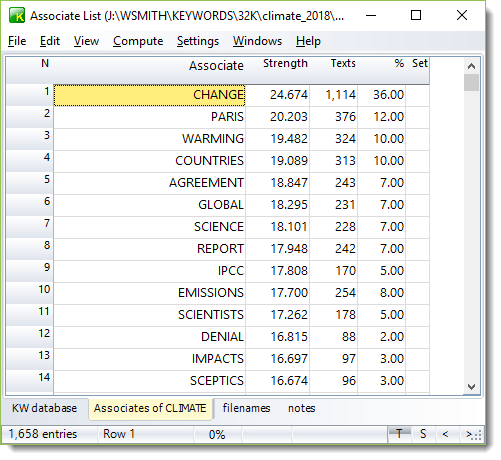
Now in the main controller key words database settings, choose a clump match percentage. The higher this is, the smaller the list of files we get will be and the more selective the criterion.
The output will now be a list of words which you could edit and use for the relevance check (Corpus Checker tool).
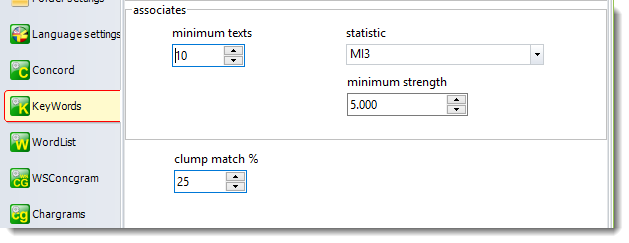
Choose Associates | follow-up in the menu, and you'll get a list of files. If you double-click one, you get to read it. As you see, the text does seem to be one which is definitely about climate change.
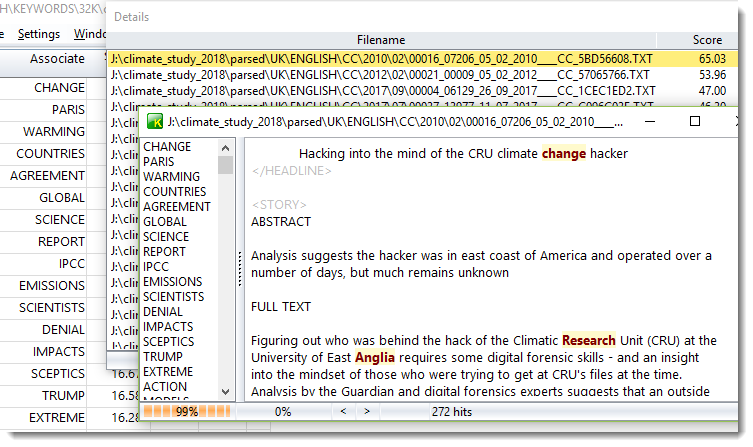
The list of terms at the left is the terms which were determined most relevant in the follow-up. Right-click to get these terms highlighted.
You can save the list as a file (right-click to see the menu). This could be input to the Corpus Checker sampler so you can evaluate your results.
