text dates and time-lines

Contents
The point of it ...
The idea is to be able to treat your text files diachronically -- that is, studying change through time.
You might want a concordance, for example, to be ordered by the text date. Or you might be interested in knowing when a certain word first appeared in your corpus and whether it gained popularity in succeeding years. Or whether the collocates of a word like web changed before 1990 and after.
This screenshot shows a time-line based on concordancing energy/emissions/carbon in about 30 million words of UK newspaper text dealing with climate change, 2000-2010.
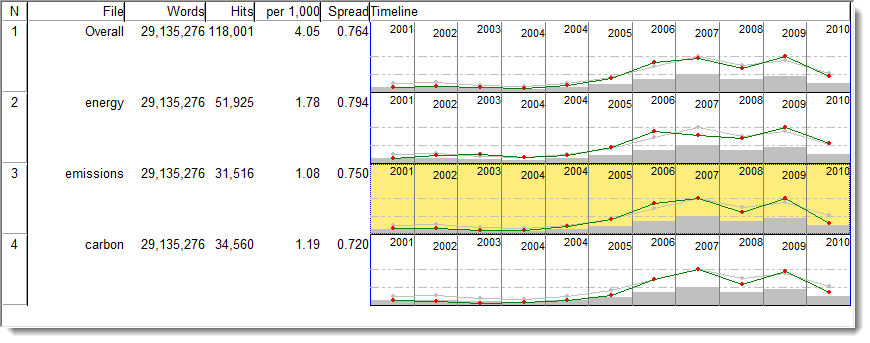
The first line shows overall data where all results on three search-terms are merged.
Concordance hits are represented as a graph with green lines and little red blobs for each time period.
The grey rectangles and the grey graph line both represent the same background information, namely the amount of word-data searched. The difference is merely that the grey line is twice as high as the rectangles below it.
The number of hits in each year is mostly roughly proportional to the amount of text being examined, though in 2006 and 2009 for the term emissions it seems that the hit rate was slightly higher. In the first half of the decade carbon was rather under-mentioned in proportion to the amount of climate-change data being studied.
See also choosing text files: setting file dates