Mark-up changes

Contents
removing all tags
would convert The<DT><the> TreeTagger<NP><TreeTagger> is<VBZ>... into The Treetagger is. Can plough through a copy of the whole BNC, for example, and make it readable. If you have specified a header string it will cut the header up to that point too. Uses the selected span for looking for the next > when it finds a <.
The Helsinki corpus can come tagged like this (COCOA tags)
the_D occasion_N of_P her_PRO$ father's_N$ death_N
and this conversion procedure will change it to
<D>the <N>occasion <P>of <PRO$>her <N$>father's <N>death
Note: this procedure does not affect underscores within existing <> markup.
word_TAG to word<TAG>
converts text like
It_PP is_VBZ easy_JJ
or Stanford Log-linear POS tagger output like
It/PP is/VBZ easy/JJ
to
It<PP> is<VBZ> easy<JJ>
You will have to confirm which character such as _ or / divides the word from the tags. Note: before it starts, it will clear out any existing <> markup.
swap tag and word
converts text like
It<PP> is<VBZ> easy<JJ>
to
<PP>It <VBZ>is <JJ>easy
or vice-versa. In other words swapping the order of tags and words. The procedure effects a swap at each space in the non-tagged text sequence.
Any tags which do not qualify a neighbouring word but for example a whole sentence or a paragraph should not be swapped, so fill in the box to the right with any such tags, using commas to separate them, e.g. <s>,</s>,<p>,</p>
The Stuttgart Tree Tagger produces output like this separating 3 aspects of each word with a <tab>:
word |
pos |
lemma |
The |
DT |
the |
TreeTagger |
NP |
TreeTagger |
is |
VBZ |
be |
easy |
JJ |
easy |
to |
TO |
to |
use |
VB |
use |
. |
SENT |
. |
You will need to supply a template for your conversion.
Template syntax and examples:
1.Any number in the template refers to the data in that column number. (The is in column 1 above, DT in column 2 of the original.)
2.Only columns mentioned in the template get used in the final output.
3.Separate columns in your template with a / slash.
4.You can add letters and symbols if you like.
5.A space will get added after each line of your original.
Examples:
•the template 1/<3>/<2> will produce with the cases above The<the><DT> Treetagger<Treetagger><NP> is<be><VBZ> etc.
•the template <POS="2">/1 will produce <POS="DT">The <POS="NP">Treetagger <POS="VBZ">is etc.
It will present the text as running text, no longer in columns, but with a break every 80 characters.
entities to characters
... converts HTML or XML symbols which are hard to read such as é to ones like é. Specify these in a text file. There is a sample file pre-prepared for you, html_entities.txt, in your Documents\wsmith6 folder; look inside and you'll see the syntax.
The idea is to remove any mark-up in XML data which you really do not wish to keep. For example, in the BNC XML edition you might wish to keep only the pos="*" mark-up and remove the c5 and hw attributes.
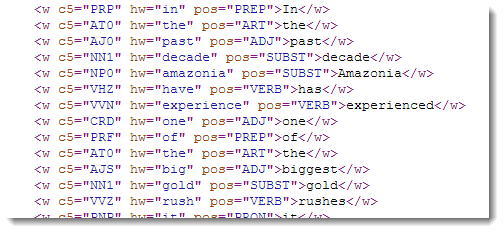
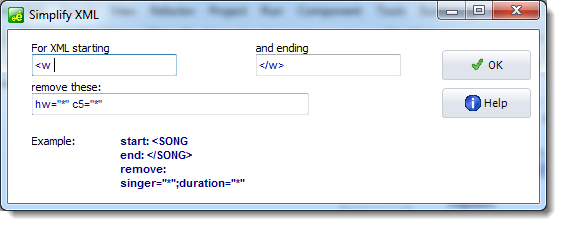
To do so, press the Options button and complete for example like this:
resulting in a saved XML file with a structure like this:
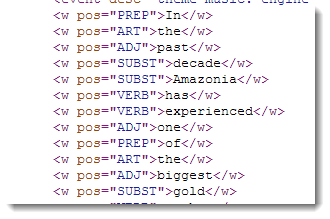
The procedure simply looks for all sections which begin and end with the required strings and delete any sections in between which contain the strings you specify in the remove these section. No further account of context is taken. Note that the order of attributes is not important, so we could have specified c5="*" first.
See also: Convert Entire Texts