|
Text Converter: extracting from files |

|

|

|
|
Text Converter: extracting from files |
|
|
|
The point of it...
The idea is to be able to extract something useful from within larger files. In the example below, I wanted to extract the headlines only from some newspaper text. I knew that the header for each text contained <DAT> (date of publication mark-up) and that the headline ended </HED>, and I wanted only those chunks which contained the phrase Leading article:.
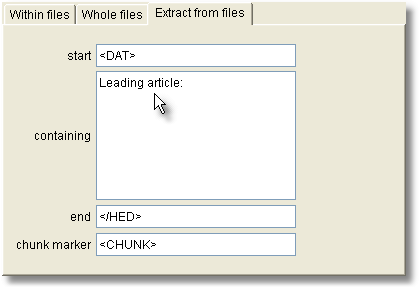
The results I got looked like this:
<CHUNK "1"><DAT>05 August 2001</DAT>
<SOU>The Observer</SOU>
<PAG>26</PAG>
<HED>Comment: Leading article: Ealing's lessons: Time for steel from the peacemakers</HED></CHUNK>
<CHUNK "2"><DAT>05 August 2001</DAT>
<SOU>The Observer</SOU>
<PAG>26</PAG>
<HED>Comment: Leading article: The free market can't house us all: Why Government has to intervene</HED></CHUNK>
<CHUNK "3"><DAT>05 August 2001</DAT>
<SOU>The Observer</SOU>
<PAG>26</PAG>
<HED>Comment: Leading article: What a turn-on: Cat's whiskers are the bee's knees</HED></CHUNK>
Settings
containing : all non-blank lines in this box will be required. Leave it blank if you have no requirement that the chunk you want to extract contains any given word or phrase.
chunk marker : Leave blank, otherwise each chunk will be marked up as in the example above, if it begins with < and ends with >. The reason for this marker is to enable subsequent splitting.
Page url: http://www.lexically.net/downloads/version5/HTML/?text_converter_extracting_from.htm

