Controller > count data frequencies
You may want to know how many of your concordance lines contain "happi*" or how many items in a word-list end in *ly. To do this, choose Summary Statistics in the Compute menu.
An Example
You have a concordance already computed. Select anywhere in the concordance lines and choose Compute : Summary Statistics. Type happi* and love in the searches window.
Press Count -- you should see something like this:
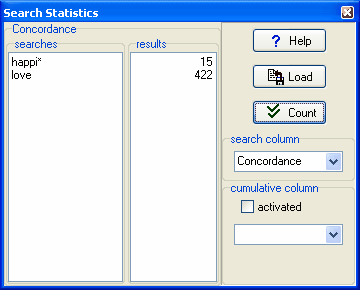
The procedure has processed all your concordance lines and found out that 15 contain happi* and 422 contain the whole word love (not loved, loves).
Search Column
This combobox lets you choose which column of data to count in.
Cumulative Column
A cumulative count adds up scores on another column of data apart from the one you are processing for your search. The columns in this combobox are of the numerical data only. Select one and ensure activated is ticked.
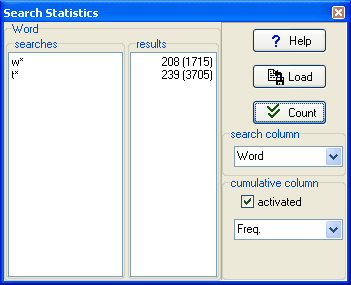
In this example, a word-list was computed and a search was made of words beginning with W or T. There are 208 of those beginning with W. In brackets you can see 1715 -- this means that the cumulative count of words beginning with W in terms of their frequency (Freq.column) is 1715, in other words an average frequency of about 8 (1715 / 208). But for the words beginning in T, although the absolute number is similar (239), the average cumulative frequency is about 15. That is because there are lots of high-frequency words beginning in T in English.
Load
This allows you to load into the searches window any plain text file which you have prepared previously.
See also: compute new column of data.