The point of it
This tab is for building up a copy of your corpus organised by months, years etc. Useful if you want to do a month-by-month analysis. Also, it is quicker to process one text file based on a month's stories rather than the 15 or 20 individual stories.
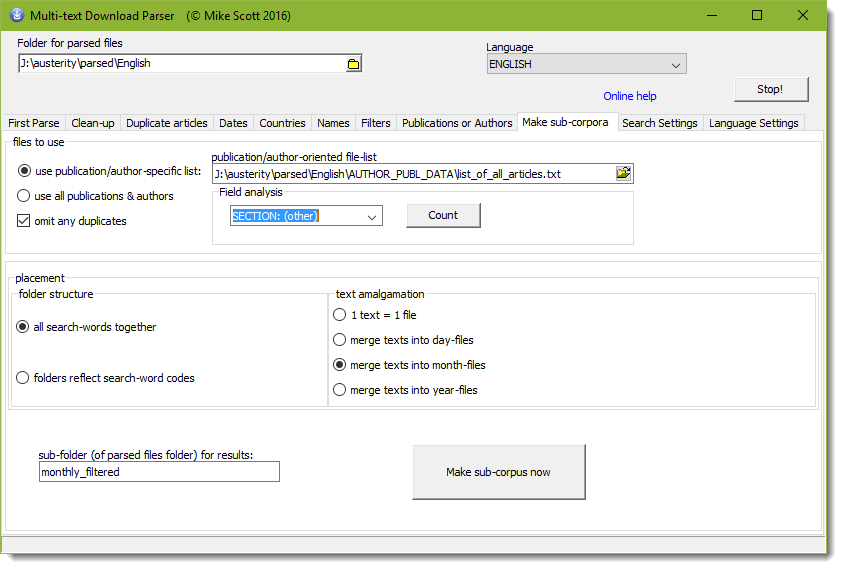
How to do it
Choose the files: either a list generated using the publications or authors above, or all the parsed files created earlier. Omit any duplicates will cut out some articles as explained above.
Folder structure
Decide whether you want results all in one folder, or split into as many folders as there were categories (such as climate change, global warming, etc.) for the current language data.
Text Amalgamation
The output can be amalgamated by merging all texts from the same date, same month or same year, if desired.
Finally, give the destination sub-folder a name such as month_based. (If using a publication-specific list the file-name of that list will be used.). When you're ready, press Make sub-corpus now. Your results will be found in a sub-folder of the SUB-CORPORA folder.
When you press Make sub-corpus now you can choose whether the articles you are copying into a sub-corpus come from the parsed collection or the filtered sub-set.
Field Analysis
The idea is to count the number of mentions of specific fields in your corpus. The procedure counts all the text files in the publication/author specific list, finds any fields and lists them for you.
>