
The point of it
The aim here is to find repeated chunks, such as can get caused
oif someone has inserted a paragraph twice by mistake
oby plagiarism
oby re-writing and editing text
oin copying and pasting.
The procedure looks essentially for repeated sentences and headings in a whole lot of texts.
How to do it
In the Settings tab with the yellow oval below, choose a folder. It will be searched as will all its sub-folders, except any called filtered.
Choose the file-types to search (default *.* ) and a tag span such as 200 characters, since mark-up gets ignored in this search. Set the minimum number of hits: the number of repetitions which you're interested in seeing in any text file. Min. length is the length of any repeated chunk.
Include unterminated sentences: includes headings.
Press  .
.
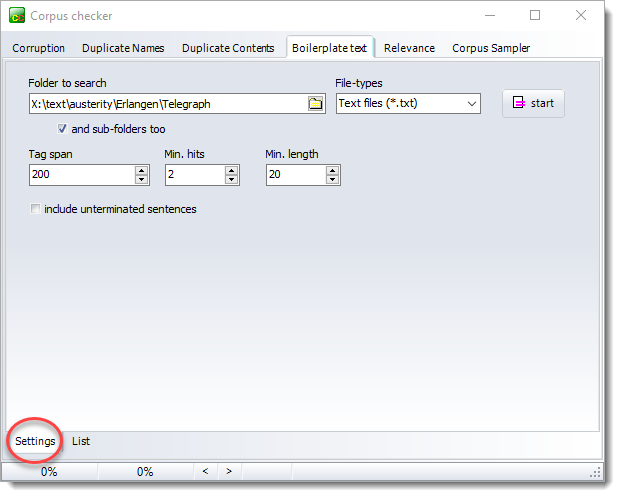
You may get results like this:
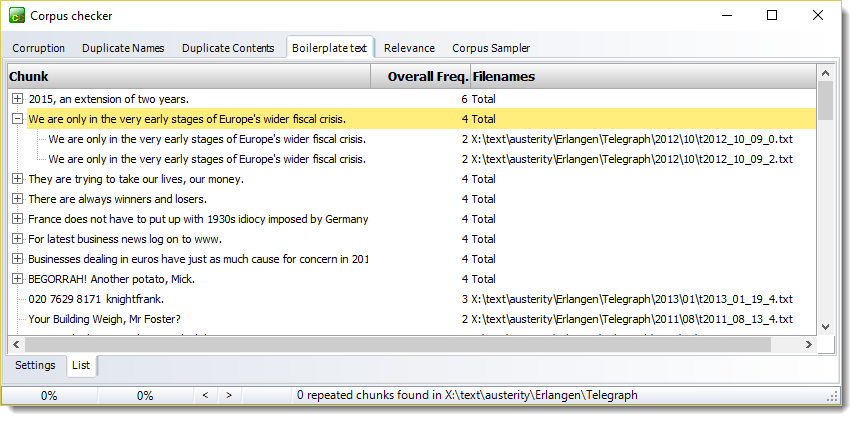
In the first case a chunk has been found repeated in 2 different text files both of the same date.
Right-click to see the text in question or to copy the list to the clipboard or to Excel.
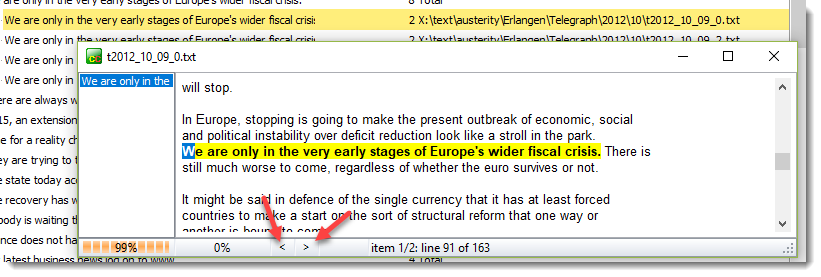
Press either of the two buttons shown by the red arrow to jump from one highlighted chunk to the next.
The top context is in the middle of the text and the sentence gets repeated at the end, possibly as a caption to a picture.
See also: duplicate file contents, corruption check, duplicate file-names,
